

Setting the Batch Input Size in a database connection can increase the performance of that connection (provided the data source itself supports batches), because instead of sending requests one at a time, a batch insert or batch update can commit multiple records in a single request.
Ordinarily, this cannot be used with the default UPSERT action for database connections. An UPSERT involves a query that first determines if the record exists so that new records can be INSERTed and existing records can be UPDATEd, but UPSERTs alternate SELECTs and INSERT/UPDATEs and cannot batched.
If you were to be able to separate the requests into INSERTs and UPATEs, however, you could batch each types, and it so happens that there is a Lookup action for most database connectors.
https://cdn.cdata.com/help/AZJ/mft/Database-Lookup.html
If you execute this lookup step into a separate step in your flow, you can determine which records are inserts and which are updates, and separate them to batch them:

Attached to this article is a sample flow, which references a simple SQLite table:
CREATE TABLE TeddyDB.dbo.Boys (
BoyID int IDENTITY(0,1) NOT NULL,
Name varchar(20) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
Age int NOT NULL,
CONSTRAINT Boys_PK PRIMARY KEY (BoyID)
);
With a few simple records in it:
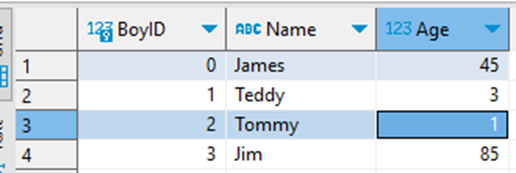
The CreateRecords step in the attached flow can be run manually from the output tab- it simply generated a preset data set with a mix of existing records and new ones:
<Items>
<Boys>
<Name>James</Name>
<Age>46</Age>
</Boys>
<Boys>
<Name>Shane</Name>
<Age>39</Age>
</Boys>
<Boys>
<Name>Tommy</Name>
<Age>2</Age>
</Boys>
<Boys>
<Name>Michael</Name>
<Age>22</Age>
</Boys>
<Boys>
<Name>Teddy</Name>
<Age>4</Age>
</Boys>
<Boys>
<Name>Tavis</Name>
<Age>26</Age>
</Boys>
<Boys>
<Name>Arturo</Name>
<Age>26</Age>
</Boys>
<Boys>
<Name>Jim</Name>
<Age>85</Age>
</Boys>
</Items>
The Lookup step in the flow uses the Lookup Action to select the primary keys from the database:
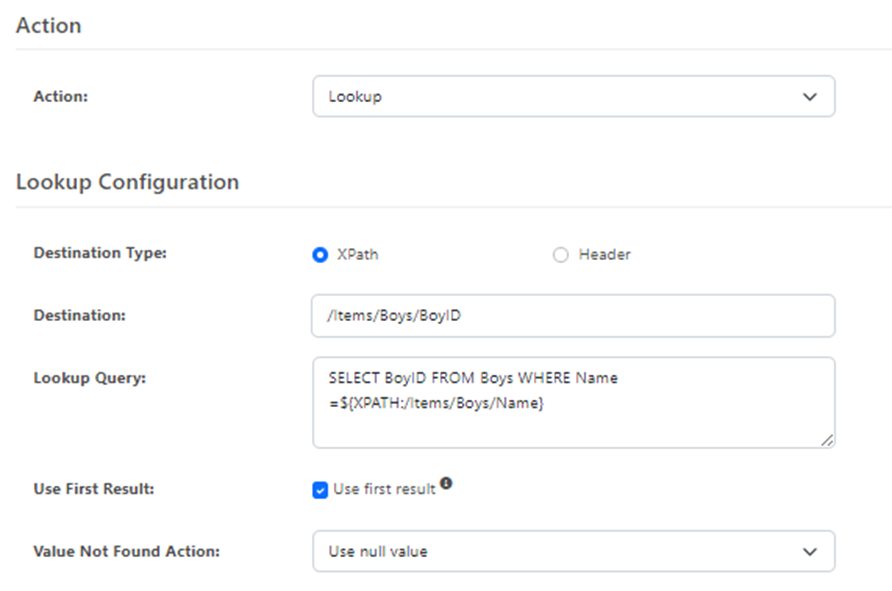
The end result of this is that some elements in the XML will be populated with their key column in the data source, and some will be null:
<Items>
<Boys>
<Name>James</Name>
<Age>46</Age>
<BoyID>0</BoyID>
</Boys>
<Boys>
<Name>Shane</Name>
<Age>39</Age>
<BoyID xsi:nil='true'></BoyID>
</Boys>
...
</Items>
NOTE: The performance in this step can be improved as well, if the data set is relatively stable, by setting a cache database to store the keys that you lookup:
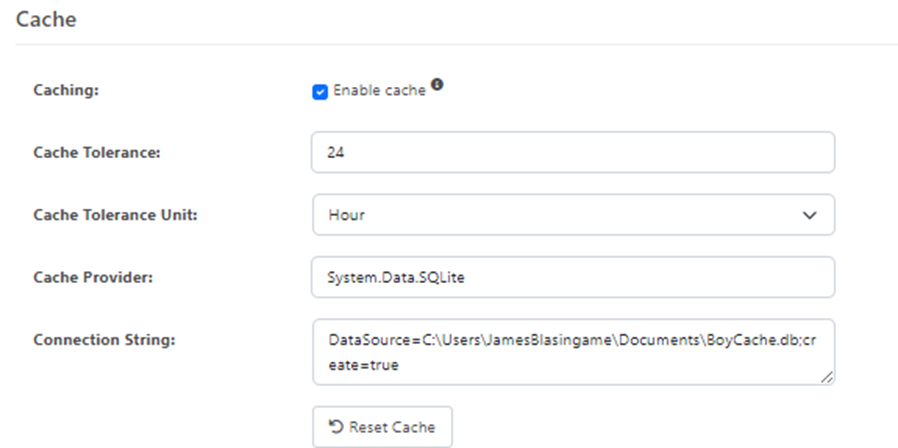
This cache will be replicated to the first time (so expect the first lookup to take longer), but then the cache will be used first if the query is within the Cache tolerance window.
After the Copy, each XML Map is used to thin out each copy of the record set - the OnlyInserts map only uses records where the key column is null:
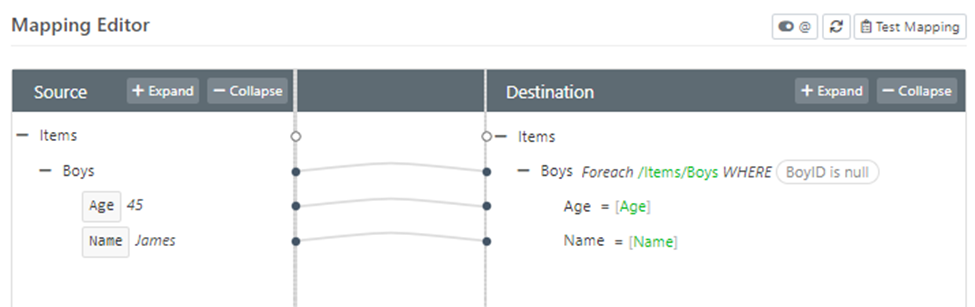
The OnlyUpdates is the complementary filter:

Finally, two copies of the Database connector will process the end result. In each case, the Batch Input Size is used to increase the size of the batch, so multiple queries are added at once, but in the InsertOnly, the Upsert action is disabled, and the key column is deselecting in the input mapping (since it's not present):

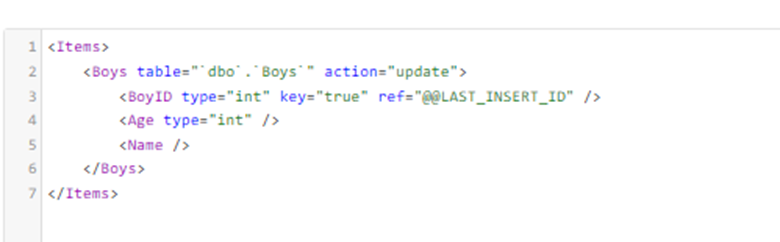
In the second (OnlyUpdates), the Upsert option is deselected, but one further step has been taken - in the code view, the action of the template is set to update:
In the logs of each connector, you can see the effect of the batching:
[2023-10-05T16:10:06.610] [Info] SQLCommand: INSERT INTO [dbo].[Boys] ([Age], [Name]) VALUES (@Age, @Name); @Age='39'; @Name='Shane'
[2023-10-05T16:10:06.611] [Info] SQLCommand: INSERT INTO [dbo].[Boys] ([Age], [Name]) VALUES (@Age, @Name); @Age='22'; @Name='Michael'
[2023-10-05T16:10:06.611] [Info] SQLCommand: INSERT INTO [dbo].[Boys] ([Age], [Name]) VALUES (@Age, @Name); @Age='26'; @Name='Tavis'
[2023-10-05T16:10:06.611] [Info] SQLCommand: INSERT INTO [dbo].[Boys] ([Age], [Name]) VALUES (@Age, @Name); @Age='26'; @Name='Arturo'
[2023-10-05T16:10:06.611] [Info] Begin executing the batch.
[2023-10-05T16:10:06.613] [Info] End execute batch.
[2023-10-05T16:10:06.613] [Info] 1 row(s) affected for the 1th query.
[2023-10-05T16:10:06.613] [Info] 1 row(s) affected for the 2th query.
[2023-10-05T16:10:06.613] [Info] 1 row(s) affected for the 3th query.
[2023-10-05T16:10:06.613] [Info] 1 row(s) affected for the 4th query.
[2023-10-05T16:10:06.613] [Info] Ending transaction: 8d13765f-6e0a-4786-bae2-8b15a8ce4a86
[2023-10-05T16:10:06.613] [Info] TransactionAction: commit
[2023-10-05T16:10:07.619] [Info] SQLCommand: UPDATE [dbo].[Boys] SET [Age] = @Age, [Name] = @Name WHERE [BoyID] = @BoyID; @Age='46'; @Name='James'; @BoyID='0'
[2023-10-05T16:10:07.619] [Info] SQLCommand: UPDATE [dbo].[Boys] SET [Age] = @Age, [Name] = @Name WHERE [BoyID] = @BoyID; @Age='2'; @Name='Tommy'; @BoyID='2'
[2023-10-05T16:10:07.620] [Info] SQLCommand: UPDATE [dbo].[Boys] SET [Age] = @Age, [Name] = @Name WHERE [BoyID] = @BoyID; @Age='4'; @Name='Teddy'; @BoyID='1'
[2023-10-05T16:10:07.620] [Info] SQLCommand: UPDATE [dbo].[Boys] SET [Age] = @Age, [Name] = @Name WHERE [BoyID] = @BoyID; @Age='85'; @Name='Jim'; @BoyID='3'
[2023-10-05T16:10:07.620] [Info] Begin executing the batch.
[2023-10-05T16:10:07.621] [Info] End execute batch.
[2023-10-05T16:10:07.621] [Info] 1 row(s) affected for the 1th query.
[2023-10-05T16:10:07.621] [Info] 1 row(s) affected for the 2th query.
[2023-10-05T16:10:07.621] [Info] 1 row(s) affected for the 3th query.
[2023-10-05T16:10:07.621] [Info] 1 row(s) affected for the 4th query.
[2023-10-05T16:10:07.621] [Info] Ending transaction: ea0411c4-70fe-4679-9d70-9077b08a79c6
[2023-10-05T16:10:07.621] [Info] TransactionAction: commit
