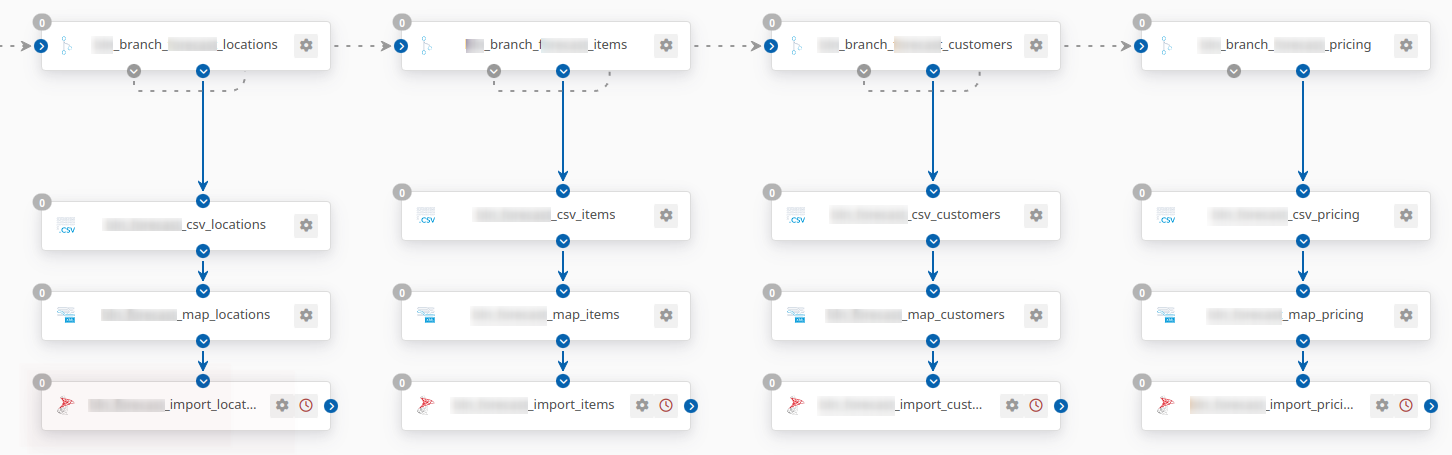
The difficulty in doing this is that each of these flows would operate asynchronously, so there isn’t a good way to tell from one SQL Server connector that all of the SQL Server connectors have finished processing, or even if they’re working on the same data set (for example. since the operation is happening asynchronously, you’d need to know that the last update to the locations table was part of the same data set that updated the items table.
With that said, it is easy enough to call a stored procedure after all of the data in a set has been uploaded by including an embedded call to the stored procedure within the input mapping:
https://cdn.cdata.com/help/AZH/mft/Database-AC.html#in-upsert-mappings
This ensures that a stored procedure call would be triggered after all of the items for one table are uploaded successfully.
My initial thought on how to approach this is to use four distinct stored procedure calls that work in parallel. Each one would update its own row in a simple staging table as ready for processing:
| Table_Type | Ready_To_Go |
|---|
| locations | false |
| items | false |
| customers | true |
| pricing | true |
And then if and only if all of the rows were true, begin processing the set, and then set all of the values to false. In this way, each path in the flow will call the stored procedure, but it’s always the last one that kicks off the process.
Is that something that you have control over?