

A common challenge that can be encountered in mapping projects occurs when a data source contains element that can be grouped into multiple transactions, but the format of the data is in a flatten data model. A simple example of this can be seen in many CSV files:
| OrderNumber | Customer | Date | Item | Qty |
|---|---|---|---|---|
| 12345 | James Blasingame | 3/17/23 | Corned Beef | 1 |
| 12345 | James Blasingame | 3/17/23 | Colcannon | 1 |
| 12346 | Teddy Blasingame | 3/17/23 | Peanut Butter | 1 |
| 12346 | Teddy Blasingame | 3/17/23 | Apples | 2 |
With the human eye, it is easy to tell that this table represents two separate transactions, each of which contains 2 line items (Orders 12345 and 12346) - but there is nothing in the CSV itself that indicates that this relationship is in place, and this information is understood by the user that is managing the file.
The CSV Connector in CData Arc can convert this into an XML structure for mapping. When doing this, it is best to configure the CSV connector so that the Connector Setting match whether or not the CSV file includes headers, and so that the Record Name is a representation of each row on the CSV. In this example, while the whole CSV represents orders, each row is representative of a line on the order, so a good representation of this data would look like:
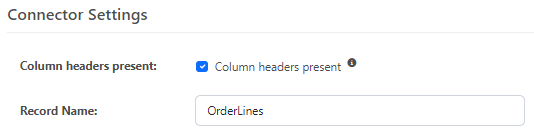
If you pass this through the CSV connector, you will see output like the following:
<?xml version="1.0" encoding="UTF-8"?>
<Items>
<OrderLines>
<OrderNumber>12345</OrderNumber>
<Customer>James Blasingame</Customer>
<Date>3/17/2023</Date>
<Item>Corned Beef</Item>
<Qty>1</Qty>
</OrderLines>
<OrderLines>
<OrderNumber>12345</OrderNumber>
<Customer>James Blasingame</Customer>
<Date>3/17/2023</Date>
<Item>Colcannon</Item>
<Qty>1</Qty>
</OrderLines>
<OrderLines>
<OrderNumber>12346</OrderNumber>
<Customer>Teddy Blasingame</Customer>
<Date>3/17/2023</Date>
<Item>Peanut Butter</Item>
<Qty>1</Qty>
</OrderLines>
<OrderLines>
<OrderNumber>12346</OrderNumber>
<Customer>Teddy Blasingame</Customer>
<Date>3/17/2023</Date>
<Item>Apples</Item>
<Qty>2</Qty>
</OrderLines>
</Items>
How do you map data in this format so that it is grouped into Orders?
NOTE: This article will proceed on the assumption that this record is generated from CSV, but there are several applicable situations that will generate XML in this structure, such as output from a stored procedure or conversion from another flat structure.
Attached to this article is a utility Script that approaches this problem by looping over each record and storing the values in the key columns in a collection in memory. It begins with two lines that are meant to be overridden based on the data used.
<!-- Hardcode this to the column to group by -->
<arc:set attr="data.keycolumn" value="OrderNumber" />
<!-- Hardcode this to the name of an element to place around each group -->
<arc:set attr="data.recordName" value="Order" />
In this script, the data.keycolumn is going to contain the element in the XML record that will be used as the key to the group (in this case, the OrderNumber column clearly identifies the order, but any column that is guaranteed to be unique across the group can be used).
The data.recordName is an element name that will be created around each grouping when outputting the resulting record into a single file. If using this script to output a single file with multiple groups, this should be set to the name of a group. In this example, the grouping is an Order, so that will be used.
There is a middle section where the document is traversed and each row is added to a collection (this section of the code is recursive and not meant to be readable):
<arc:set item="storage" />
<arc:call op="xmlDOMSearch?uri=[FilePath]&xpath=/Items/">
<arc:set attr="data.rowname" value="[xname]" />
<arc:set attr="data.key" value="[xpath([data.keycolumn])]" />
<arc:check attr="data.key">
<arc:set attr="order_number" value="[data.key]" />
<arc:set attr="current_row">
<[data.rowname]>
<arc:call op="xmlDOMSearch?xpath=*">
<[xname]>[xpath('.') | xmlencode]</[xname]>
</arc:call>
</[data.rowname]>
</arc:set>
<arc:set attr="storage.[order_number]" value="[storage.[order_number] | def('')]\r\n[current_row]" />
</arc:check>
</arc:call>
But following this, there are two code blocks that will handle the group output differently. In the first block, the input document is split into individual files based on the unique keys. This section is commented out, but if uncommented:
<!-- Split into one file per unique key -->
<arc:set attr="output.fileprefix" value="[Filename | split('.', 1)]" />
<arc:enum item="storage">
<arc:set attr="output.filename" value="[output.fileprefix]_[_attr].xml" />
<arc:set attr="output.data">
<Items>
[_value]
</Items>
</arc:set>
<arc:push item="output" />
</arc:enum>
Then the Script will split each group into a separate output file, named based on the key, for example, like Order_12345.xml:
<Items>
<OrderLines>
<OrderNumber>12345</OrderNumber>
<Customer>James Blasingame</Customer>
<Date>3/17/2023</Date>
<Item>Corned Beef</Item>
<Qty>1</Qty>
</OrderLines>
<OrderLines>
<OrderNumber>12345</OrderNumber>
<Customer>James Blasingame</Customer>
<Date>3/17/2023</Date>
<Item>Colcannon</Item>
<Qty>1</Qty>
</OrderLines>
</Items>
The default behavior, however, is at the bottom of the script, and if left in place:
<!-- Keep one file with all records grouped into children -->
<arc:set attr="output.fileprefix" value="[Filename | split('.', 1)]" />
<arc:set attr="output.data">
<Items>
<arc:enum item="storage">
<[data.RecordName]>
[_value]
</[data.RecordName]>
</arc:enum>
</Items>
</arc:set>
<arc:set attr="output.filename" value="[output.fileprefix].xml" />
<arc:push item="output" />
This keeps all of the records in the same file, but uses the data.recordName as a grouping element in the output:
<Items>
<Order>
<OrderLines>
<OrderNumber>12345</OrderNumber>
<Customer>James Blasingame</Customer>
<Date>3/17/2023</Date>
<Item>Corned Beef</Item>
<Qty>1</Qty>
</OrderLines>
<OrderLines>
<OrderNumber>12345</OrderNumber>
<Customer>James Blasingame</Customer>
<Date>3/17/2023</Date>
<Item>Colcannon</Item>
<Qty>1</Qty>
</OrderLines>
</Order>
<Order>
<OrderLines>
<OrderNumber>12346</OrderNumber>
<Customer>Teddy Blasingame</Customer>
<Date>3/17/2023</Date>
<Item>Peanut Butter</Item>
<Qty>1</Qty>
</OrderLines>
<OrderLines>
<OrderNumber>12346</OrderNumber>
<Customer>Teddy Blasingame</Customer>
<Date>3/17/2023</Date>
<Item>Apples</Item>
<Qty>2</Qty>
</OrderLines>
</Order>
</Items>
In this manner, this utility script can restore the order grouping to the XML produced from the output file (either because each file is an order, or a hierarchy is restored to the structure), and subsequent XML Map tools can process this data by order.
