I know that I can define an out environment variable in pre-job event and use that in the task replication query (documented here and here excellently).
I’m probably stretching here but can I define that out-variable to read from a file or any other source and then run the sync task for ALL values of that variable? Kind of a loop?
Thanks in advance for you answers!
Best answer by Ergesta R
Hi @CJIW, Apologies for the late reply here. Yes, it is possible to achieve such scenario in Sync using pre and post job events.
To offer a clearer illustration of how this can be accomplished, in the following I will provide an example.
Let’s suppose that we need to replicate data from SQLServer to Snowflake.
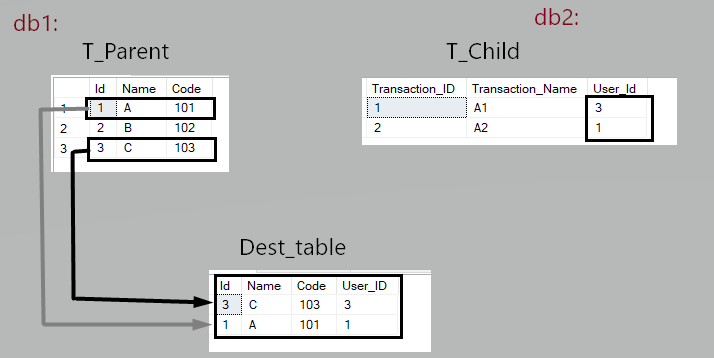
> In one SQLServer database we have the ‘T_Parent’ table that is used only by the HR department and contains detailed information for all the registered users. >And on another database the ‘T_Child’ table contains only the users that have made at least one transaction. This one is accessed by the Accounting department and when a user performs a transaction, it is added to this table and linked with a Transaction_ID (which is greater than the previous values).
In the destination, we aim to have only those records from the T_Parent table that have associated transactions (are present in the T_Child table), as illustrated in the diagram below:
Initially, we need to manually create a file that will store a numeric value representing the number of transactions of the 'T_Child' table, serving as a counter. The initial value to be stored in this file is 1.
Note:This file should be placed in a location where Sync has read and write access.
Pre-job event:
In the pre-job event, we need to check if there are new records added to the T_Child table that have not been replicated in the destination. If so, to get the User_Id of that record, to use in the replicate query.
Pre-job event script:
<!-- Code goes here -->
<!-- at first we need to read the value saved in the counter file -->
<!-- this value corresponds with the nr of the transactions/rows +1 -->
In Post-job event, we should check if all the records have been replicated. If not and the last run has been successful, we should raise the value of the counter File and rerun the job.
Post-job event script:
<!-- Code goes here -->
<!--reading the value saved in the counter file -->
Hi @CJIW, Apologies for the late reply here. Yes, it is possible to achieve such scenario in Sync using pre and post job events.
To offer a clearer illustration of how this can be accomplished, in the following I will provide an example.
Let’s suppose that we need to replicate data from SQLServer to Snowflake.
> In one SQLServer database we have the ‘T_Parent’ table that is used only by the HR department and contains detailed information for all the registered users. >And on another database the ‘T_Child’ table contains only the users that have made at least one transaction. This one is accessed by the Accounting department and when a user performs a transaction, it is added to this table and linked with a Transaction_ID (which is greater than the previous values).
In the destination, we aim to have only those records from the T_Parent table that have associated transactions (are present in the T_Child table), as illustrated in the diagram below:
Initially, we need to manually create a file that will store a numeric value representing the number of transactions of the 'T_Child' table, serving as a counter. The initial value to be stored in this file is 1.
Note:This file should be placed in a location where Sync has read and write access.
Pre-job event:
In the pre-job event, we need to check if there are new records added to the T_Child table that have not been replicated in the destination. If so, to get the User_Id of that record, to use in the replicate query.
Pre-job event script:
<!-- Code goes here -->
<!-- at first we need to read the value saved in the counter file -->
<!-- this value corresponds with the nr of the transactions/rows +1 -->
In Post-job event, we should check if all the records have been replicated. If not and the last run has been successful, we should raise the value of the counter File and rerun the job.
Post-job event script:
<!-- Code goes here -->
<!--reading the value saved in the counter file -->