
If you have an error like
Unexpected multi-valued result was returned for XMLTable column ...
you try to address a PATH in an XML document, that occurs multiple times.
Example.
Imagine you have this JSON document:
{
"data": [{
"type": "articles",
"id": "1",
"attributes": {
"title": "JSON API paints my bikeshed!",
"body": "The shortest article. Ever.",
"created": "2015-05-22T14:56:29.000Z",
"updated": "2015-05-22T14:56:28.000Z"
},
"relationships": {
"author": {
"data": {"id": "42", "type": "people"}
}
}
}],
"included": [
{
"attributes": "a",
"attributes": "b",
"attributes": "c"
}
]
}
this will be processed to XML using jsontoxml into
<?xml version='1.0' encoding='UTF-8'?>
<root xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<data>
<type>articles</type>
<id>1</id>
<attributes>
<title>JSON API paints my bikeshed!</title>
<body>The shortest article. Ever.</body>
<created>2015-05-22T14:56:29.000Z</created>
<updated>2015-05-22T14:56:28.000Z</updated>
</attributes>
<relationships>
<author>
<data>
<id>42</id>
<type>people</type>
</data>
</author>
</relationships>
</data>
<included>
<attributes>a</attributes>
<attributes>b</attributes>
<attributes>c</attributes>
</included>
</root>
To process this, there are 3 possibilities to solve this:
1) address the multi-valued attributes using an indexed path expression
SELECT
"xmlTable.idColumn",
"xmlTable.firstelem",
"xmlTable.secondelem",
"xmlTable.thirdelem"
FROM
(call "json".getFiles('test.json')) f,
XMLTABLE(XMLNAMESPACES( 'http://www.w3.org/2001/XMLSchema-instance' as "xsi" ),'/root/included' PASSING JSONTOXML('root',to_chars(f.file,'UTF-8'))
COLUMNS
"idColumn" FOR ORDINALITY,
"firstelem" STRING PATH 'attributes[1]',
"secondelem" STRING PATH 'attributes[2]',
"thirdelem" STRING PATH 'attributes[3]'
) "xmlTable";;
The disadvantage of this approach is, that you have to know how much attributes you expect.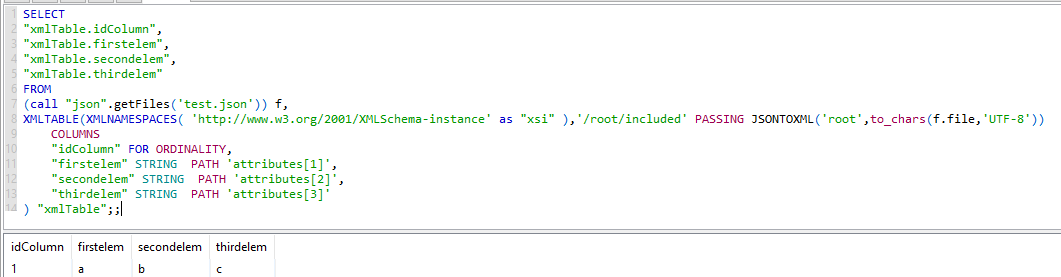
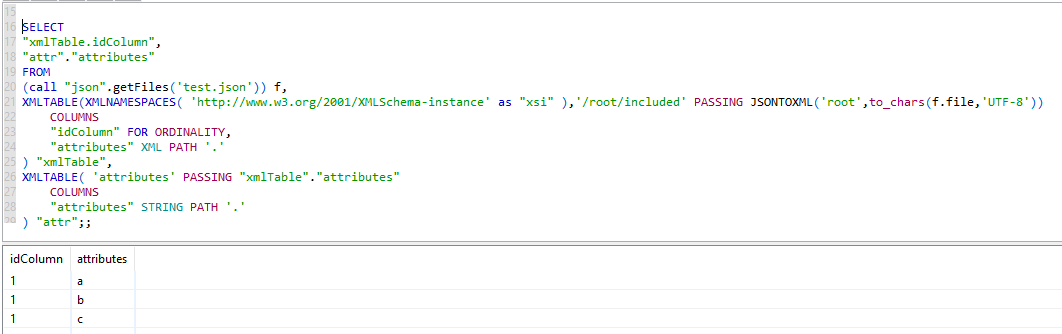
2) multiple XMLTABLE parsing
SELECT
"xmlTable.idColumn",
"attr"."attributes"
FROM
(call "json".getFiles('test.json')) f,
XMLTABLE(XMLNAMESPACES( 'http://www.w3.org/2001/XMLSchema-instance' as "xsi" ),'/root/included' PASSING JSONTOXML('root',to_chars(f.file,'UTF-8'))
COLUMNS
"idColumn" FOR ORDINALITY,
"attributes" XML PATH '.'
) "xmlTable",
XMLTABLE( 'attributes' PASSING "xmlTable"."attributes"
COLUMNS
"attributes" STRING PATH '.'
) "attr";;
The advantage is, that you are independent of the number of attributes. The rows will be expanded automatically. The disadvantage is, that the attributes path must be always not empty, otherwise, you will miss this row completely.
3) Use arrays. This works since Datavirtuality RELEASE-1.8.35
SELECT
"xmlTable.idColumn",
"xmlTable.attributes",
array_get("xmlTable.attributes", 1) as "firstelem",
array_get("xmlTable.attributes", 2) as "secondelem",
array_get("xmlTable.attributes", 3) as "thirdelem"
FROM
(call "json".getFiles('test.json')) f,
XMLTABLE(XMLNAMESPACES( 'http://www.w3.org/2001/XMLSchema-instance' as "xsi" ),'/root/included' PASSING JSONTOXML('root',to_chars(f.file,'UTF-8'))
COLUMNS
"idColumn" FOR ORDINALITY,
"type" STRING PATH 'type',
"id" STRING PATH 'id',
"attributes" STRING[] PATH 'attributes'
) "xmlTable";;
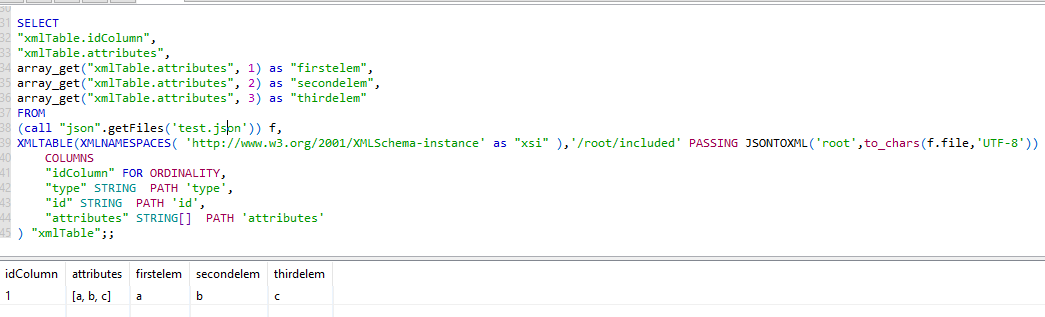
The advantage of this approach is, that you can decide afterwards, what array fields you want to choose or not. This is very useful, if you process the output in (stored) procedures where you can operate with all array functions and loops etc, to extract your data.
