
Overview:
It is sometimes the case where a programmer needs to perform multiple inserts and updates to the data from one source table to a target table. It is in these scenarios, that it is beneficial to use a procedure which can support both of these functions simultaneously, increasing the efficiency of the query. SQL users will be familiar with the MERGE statement, which migrates changes from a source table to a destination table, however in Data Virtuality, the solution is to utilize the Upsert Stored Procedure or to enable an Upsert Job.
Uses:
There are a few different approaches to take when merging changes from the source table to the target table, however some key elements are required. An identity field or an array of key fields is used by DV to determine which rows from the source table can be compared to the rows in the target table, and which rows need to be added versus which rows need to be updated. We must then also specify the column or an array of columns to be updated once a match is made on the key field. Finally, we will need to specify the source and target tables, which can be a combination of tables inside or outside of the dwh. Some optional options here is providing a surrogate key, an auto-incrementing column, or a checkMaxFieldId.
Take for example, our target table "test1":
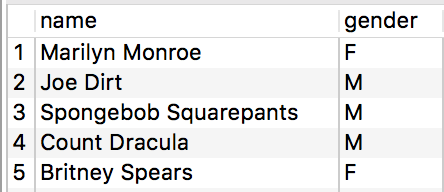
And our source table "test1_tmp":
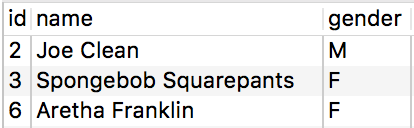
We need to sync the changes from the source table, by making the needed updates and then inserting any new rows. After calling the "UTILS.upsert" stored procedure, like so:
call "UTILS.upsert"(
"source_table" => 'dwh.test1_tmp',
"keyColumnsArray" => ARRAY('id'),
"updateColumns" => ARRAY('name','gender'),
"invertUpdateColumns" => FALSE,
"target_table" => 'dwh.test1'
);;
The resulting target table now looks like:
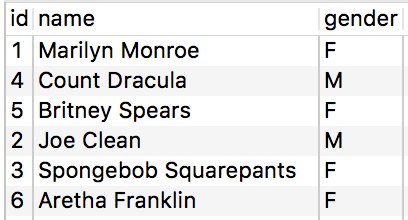
Additionally, we can use this method when replicating data from the virtual schemas into the analytical storage. Using the Replication Job wizard, shown below using the Facebook data source as an example, check the columns to be updated and the identity field to compare.
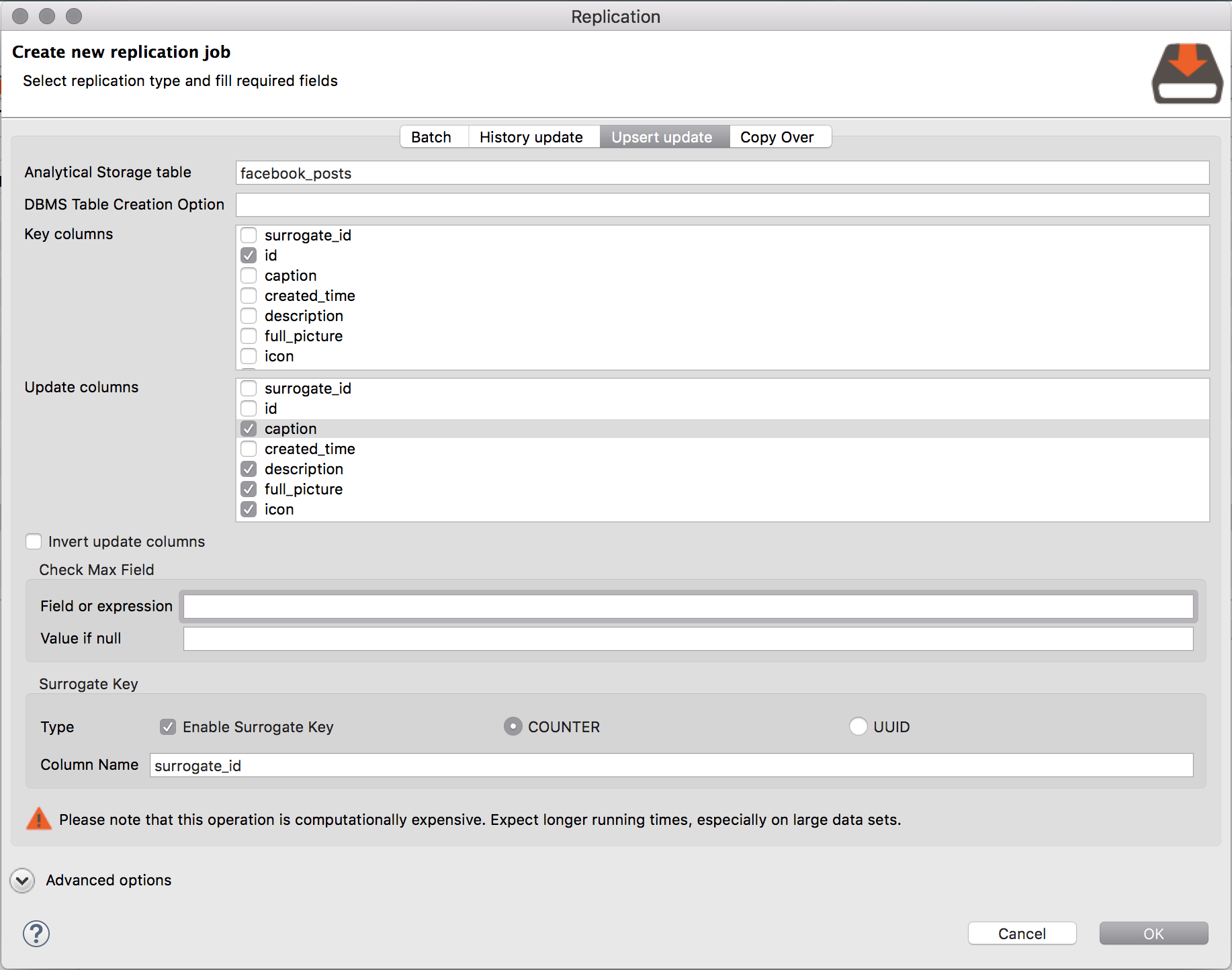
Conclusion:
The next option here could be to add a schedule to the upsert job in order to automate your processes. By using the Upsert stored procedure or the Upsert replication job, we can now take code that previously took multiple steps and reduce it down to one step.
Example uses and more information can be found in the user documentation here.
