
CData Arc is a web application solution for creating complex document processing flows, and because of the variety of environments that you can run the application in, the number of processes that you can configure the application to run with, and factors of the local environment, performance, and resource consumption in CData Arc can vary widely from one installation to another. Because you can design any number of disparate business processes in Arc, you can see impacts on performance based on the number of tasks that you give Arc to perform, and the resources that you give Arc to work with.
This article will discuss some of the resources that Arc works with and how you can evaluate them to make sure you are providing the application with everything that it needs to handle the tasks that you allocate to it. This article discusses all implementations of Arc, but details relevant to Arc Cloud are highilghted in a special section at the end.
Primary Architecture: Arc works with several components of the environment to process the messages that you provide it, and the key factors are:
The application directory on the system disk is relied on heavily for storage of messages in transit, logging, and storage of the profile and connector configuration. Storage of the connector configuration ensures reliable operations, but because of this, a key factor in performance of the application is the performance of the disk. A network share can be used as the application directory, but low disk latency is key to performance, so when using a network share or EFS, make sure that the drive is in the same data center as the application to help ensure the lowest possibly latency.
Arc also uses a backend database for storage of message processing metadata, application logging, audit and access logic, and state storage of different connector metadata (such as last operation times for automated processes and incremented vales such as EDI control numbers). Arc can operate even when the connection to the database is interrupted, so the application can recover from a temporary disconnection to the database, but poor performance of the database can lead to downstream effects of the performance of the application.
The speed of the connection to the database is a factor as well as the volume of data that is maintained in the database. Notably, CData Arc is distributed by default with a disk-based database (SQLite in Windows installations of CData Arc, and Derby for Java/Cross-Platform installations) that provides suitable performance for modest volumes of traffic. While these disk-based databases are provided with the application by default and do not require any additional configuration, they are not designed to scale performance with large volumes of records (100K or more entries).
If these disk-based databases grow in volume to incorporate large volumes of data, there will be effects in performance on both speed and CPU usage (since working with larger database files will scale up the consumption of memory and CPU usage). If you anticipate processing large production volumes of records, it is recommended that you configure an external connection to an enterprise capable database as early as possible. Supported databases include SQL Server, PostgreSQL, and MySQL, and you need only configure a connection string to the database in the server configuration:
Windows database configuration: https://cdn.cdata.com/help/AZK/mft/Windows-Edition.html#configuring-the-application-database
Java/cross-platform database configuration: https://cdn.cdata.com/help/AZK/mft/Cross-Platform-Edition.html#configure-the-application-database
Additional factors:
The application will run in process on the machine, so several aspects of the local environment will be a factor:
The available memory on the machine will be allocated for the use of the application, and if the available memory is reached, this can affect performance. In Windows, this is based on the amount of available memory on the machine (although you can force stricter limits if you host the application in IIS) and in Java environments, this is based on the JVM options that the servlet container is started with.
The available disk space will not have an impact on performance so long as adequate disk space is available, but a full disk can affect performance and a disk that is out of space will cause fatal errors for the application, so keeping regular maintenance on the system disk is needed.
The available CPU will have an impact on performance, but this is generally not a major factor unless the CPU power is more limited than what is available on modern operating systems or if a factor in the flow configuration leads to aggravated use of the CPU (one example being the increase when working with a large, disk-based database).
Finally, network performance can influence overall performance of the application and administration console, especially if slow network performance leads to delays in MFT transfers of documents to your partners.
In general, if any of these additional factors is adequate and still being overtaxed, it is likely that either limitations in the configuration of the system disk or backend database is leading to a situation that is exhausting one of these resources (especially if performance worsens over time for the same volume of message processing) or that one of the scheduled processes within Arc is causing the application to exhaust a system resource.
Running an in-app check on the disk and database performance:
CData Arc will run a periodic health check to alert you if a resource is being overtaxed - if the memory usage or disk usage approaches the limit of what’s available, or if the database has a large number of records in it, but these checks are intended more to warn you about approaching limitations than to test performance.
If you have a Professional Edition license of CData Arc or higher, you can make use of the administrative API in CData Arc to run some basic checks and get a sense for the health of the application disk and database.
The attached arcflow includes a series of checks to list the connectors and workspaces on disk (checking the performance of the system disk) and listing the entries in the app_transactions and app_logs database tables (checking the performance of the database):
<!-- This script requires the authtoken of a user with API access -->
<arc:set attr="diag.authtoken" value="OBTAIN AN API ACCESS TOKEN FROM THE USERS TAB" />
<arc:set attr="tmp.workspaceList" />
<arc:set attr="tmp.connectorList" />
<!-- list the workspaces -->
<arc:set attr="diag.diskcheckStart" value="[now()]" />
<arc:call op="api.rsc/workspaces" item="diag" httpmethod="GET">
<arc:set attr="tmp.workspaceList" value="[tmp.workspaceList | concat([diag.WorkspaceID])]\r\n" />
<arc:set attr="tmp.workspaceCount" value="[_index]" />
</arc:call>
<arc:set attr="tmp.workspaceListTime" value="[diag.diskcheckStart | datediff('second') | abs]"/>
<arc:set attr="output.data" value="[tmp.workspaceList]\r\nListed [tmp.workspaceCount] workspaces in [tmp.workspaceListTime] seconds. "/>
<arc:set attr="output.filename" value="WorkspaceCheck_[tmp.workspaceListTime | greaterThan(2,'UNHEALTHY','HEALTHY')].txt" />
<arc:push item="output" />
<!-- list the connectors -->
<arc:set attr="diag.connectorcheckStart" value="[now()]" />
<arc:call op="src/listConnectors.rsb?idonly=true" item="diag" httpmethod="GET">
<arc:set attr="tmp.connectorList" value="[tmp.connectorList | concat([diag.portid | def])]\r\n" />
<arc:set attr="tmp.connectorCount" value="[_index]" />
</arc:call>
<arc:set attr="tmp.connectorListTime" value="[diag.connectorcheckStart | datediff('second') | abs]"/>
<arc:set attr="output.data" value="[tmp.connectorList]\r\nListed [tmp.connectorCount] connectors in [tmp.connectorListTime] seconds. "/>
<arc:set attr="output.filename" value="ConnectorCheck_[tmp.connectorListTime | greaterThan(5,'UNHEALTHY','HEALTHY')].txt" />
<arc:push item="output" />
<arc:set attr="tmp.diskCheckTime" value="[diag.connectorcheckStart | datediff('second') | abs]"/>
<arc:set attr="output.data" value=""/>
<arc:set attr="output.filename" value="Disk check is [tmp.diskCheckTime | greaterThan(5,'UNHEALTHY','HEALTHY')]" />
<arc:push item="output" />
<!-- database checks -->
<arc:set attr="tmp.DatabaseCheckStart" value="[_ | now()]" />
<arc:call op="api.rsc/transactions" item="diag" httpmethod="GET">
<arc:set attr="tmp.transactionCount" value="[_index]" />
</arc:call>
<arc:set attr="tmp.DatabaseCheckTime" value="[tmp.DatabaseCheckStart | datediff('second') | abs]"/>
<arc:set attr="output.filename" value="Pulling [tmp.transactionCount] transactions from app_transactions check is [tmp.DatabaseCheckTime | greaterThan(10,'UNHEALTHY','HEALTHY')]" />
<arc:push item="output" />
<arc:set attr="tmp.DatabaseCheckStart" value="[_ | now()]" />
<arc:call op="api.rsc/logs" item="diag" httpmethod="GET" >
<arc:set attr="tmp.logCount" value="[_index]" />
</arc:call>
<arc:set attr="tmp.DatabaseCheckTime" value="[tmp.DatabaseCheckStart | datediff('second') | abs]"/>
<arc:set attr="output.filename" value="Pulling [tmp.logCount] logs from app_logs check is [tmp.DatabaseCheckTime | greaterThan(10,'UNHEALTHY','HEALTHY')]" />
<arc:push item="output" />
C:\Users\<User Name>\Downloads\DiagnosticReport.arcflow
To use this script, obtain an API token from a user in the Users section that is authorized to use the API and set it as the argument for “diag.authtoken”:
https://cdn.cdata.com/help/AZK/mft/User-Roles.html#admin-api-access
Then, to execute the diagnostic, navigate to the Output tab and select the Receive button:
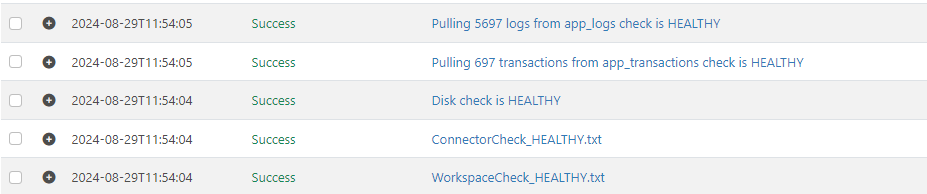
The Script will make a rough estimate of how long it takes to poll the primary resources used in the application. The times of each check here (5 seconds to count the connectors and 10 seconds for the count of the records in each database) may need to be adjusted if you have larger numbers of entries, but the objective is to get a sense for how quick each resource is to respond, and if you are experiencing performance issues, can point you to the resource where you might wish to take action.
Disk Management
If listing the connectors on disk is slow: You may wish to check the available space on the disk to see if there is adequate space remaining. You can initiate cleanup of the application’s resources in the Settings (cogwheel) -> Advanced-> Cleanup Options section of the application, but since this is done on a regular basis, you may also wish to use a disk checking utility to see if there are folders on the disk with a large volume of entries.
If you are using a network location or mounted drive, please check the location of the drive to make sure it has low latency.
If you are quickly filling up your disk: you may wish to consider disabling some of the logging configuration in your connectors, especially if you do not review the logs for transmissions. Each connector will have three settings that you can adjust in the Settings or Advanced tab (depending on the connector) to modify the disk usage of that connector.
Message->Save to Sent Folder will save a copy of sent files with any message context removed into a Sent folder for that connector. This is a legacy setting from earlier releases of CData Arc where an external application might look for the presence of files in the Sent folder to confirm delivery, and unless you are actively monitoring for these Sent files, this can be disabled (for new connectors, this will default to false).
Logging->Log Level will impact the amount of detail that is written to log files on disk, and the more verbose the logging, the larger the log files maintained by the application. Debug logging and higher should only be used while troubleshooting a connector or when requested by the support team, and should be returned to Info when done. If you are concerned about the size of the disk space, and the logging can be set lower than the default of Info if you do not need to review logs for this connector.
Logging->Log Messages will maintain a copy of the current state of the message, with message context, as a part of the logs that are accumulated for that connector. If you are processing very large messages in multiple steps in the flow, consider disabling this option for connectors that you do not need to adjust or reprocess through often. Disabling the Log Messages option will mean that you will not be able to download a copy of the message in the Input and Output tabs for that connector or requeue messages at that connector, but you may still do so from an earlier or later connector in your flow where the Log Messages option is enabled.
Database Management
If you are using the default database please note it is only intended for modest volumes of traffic. If you are maintaining large numbers of records in the database, your best option to improve performance will be to make sure that the application is connected to a production capable database, such as SQL Server, PostgreSQL, or MySQL, and that the network connection to this database is fast.
If you remain on the default database, you can expect to encounter performance impacts at higher volumes, but you can mitigate this by shortening the history that is retained in the database by setting the cleanup interval in the Settings (cogwheel) -> Advanced-> Cleanup Options to a lower value.
Additionally, please note that disk-based databases like SQLite and Derby are present as files on disk, in a db folder in the application directory (SQLite databases in .db files and Derby databases existing as subfolders to db). Disk-based databases that are very large can be renamed or deleted, and Arc will attempt to restart that database anew – this can be used to quickly restore the performance of the application against a database that was too large to manage, at the cost of losing access to the history maintained in that database from CData Arc (app_transactions maintains the metadata of the transaction history, and app_logs maintains the history of the application log for errors and status notifications).
If you are using a production database and it is still performing slowly, please consider cleaning up older records from the database using a database management utility. If the DB is configured on an external or cloud based server, check the latency of the connection to the database.
If your database is quickly filling with records, please review the Application Log from the Activity->Application menu to see if there are persistent errors that recur in the runtime of the application. Ordinarily, you should expect normal processing errors to accumulate here as Arc processes messages and encounters expected errors, but if you see the same exception appearing regularly, it may indicate a problematic process that needs to be addressed to restore performance, or to avoid flooding the database with unnecessary traffic.
Special considerations for Arc Cloud:
The hosted instances of Arc Cloud do not have the same configuration options available to on-premise and cloud hosted instances of Arc. Notably, the database configuration uses PostgreSQL and is not configurable, and direct access to the system disk is not available. Because of this, the performance considerations of disk-based databases are not an issue, and you can be certain that there is low latency when accessing the disk and database.
As with other instances of CData Arc, heavy message processing in CData Arc can still influence performance, but as Arc Cloud instances are provided with a fixed volume of space on disk, you will want to be mindful of tasks that can quickly fill up the available space on disk. Automated health checks for the consumption of the disk will alert the application administrator as it starts to fill but if you do not act on these checks or the disk fills before you have a chance to act, a full disk will impact the processing of messages in the application. Please review the sections titles If you are quickly filling up your disk and If your database is quickly filling with records above if these are issues in your environment.
