

Table of Contents
Introduction
In today's rapidly evolving cloud infrastructure landscape, automation has become essential for maintaining efficiency and reliability in deployments. By combining the powerful data integration capabilities of CData Sync with the infrastructure automation prowess of Terraform, organizations can achieve a streamlined and repeatable deployment process that significantly reduces operational overhead.
This article demonstrates how to automate the deployment of CData Sync in AWS using Terraform. We'll explore the step-by-step process of setting up a fully automated infrastructure, including network configuration, security groups, and EC2 instances. This automation approach significantly reduces manual intervention, ensures consistency, and speeds up the deployment process while following infrastructure-as-code best practices.
Overview of CData Sync
CData Sync is an intuitive and robust data integration tool that streamlines the replication, integration, and transformation of data across numerous sources. It supports a wide range of cloud services, databases, and applications, enabling businesses to maintain unified and up-to-date datasets effortlessly. Featuring a user-friendly web-based interface, CData Sync ensures consistent and accessible data across multiple platforms.
Overview of Terraform
Terraform is an open-source Infrastructure as Code (IaC) tool developed by HashiCorp. It enables users to define, provision, and manage infrastructure using a declarative configuration language. Terraform is widely used to automate the setup and management of cloud resources across various providers such as AWS, Azure, Google Cloud, and others
Benefits of CData Sync automation with Terraform
Automating the deployment of CData Sync in AWS using Terraform brings several advantages, including:
- Infrastructure as Code (IaC)
- By leveraging Terraform, you define your AWS infrastructure (e.g., ECS, VPCs, IAM roles) as code, which enables version control (i.e. tracking and managing changes to your infrastructure through Git or other version control systems) and reproducibility (i.e. replicating the same infrastructure in different environments, such as development, testing, production).
- Consistency
- Terraform ensures that infrastructure is deployed consistently, eliminating configuration drift and reducing the risk of human error during manual deployments.
- Scalability
- With Terraform, you can easily scale your CData Sync deployment to accommodate growing workloads by adjusting configuration parameters (e.g., EC2 instance type and EBS volume, ASG, VPC).
- Performance
- Automating the deployment process drastically reduces the time needed to provision and configure resources, enabling faster project setups and iterations.
- Cost Optimization
- Terraform allows for automated cleanup of unused resources, ensuring cost-effective management of AWS services. You can also deploy only the necessary components during non-peak hours to further optimize costs.
- Cross-Cloud Compatibility
- Terraform's provider-agnostic architecture allows you to extend your deployment to other cloud providers or hybrid environments, enabling future flexibility without rework.
- Seamless Updates & Rollbacks
- Infrastructure changes can be applied and rolled back with minimal effort, ensuring safe updates to your deployment and quick recovery in case of issues.
- Integration with CI/CD pipelines
- Terraform scripts and state can be migrated into HCP Terraform (Cloud), which enables the integration between IaC and CI/CD pipelines, hence enabling fully automated deployments whenever new changes are committed to the codebase.
- Disaster Recovery
- Terraform enables easy recreation of your entire cloud infrastructure and Sync from scratch in case of failures, ensuring business continuity.
Prerequisites
Before proceeding with the deployment of CData Sync in AWS via Terraform, ensure the following requirements are met:
- Terraform
- Install Terraform on your local machine. You can download Terraform from the official website.
- Verify the installation by running
terraform -vcommand.
- CData Sync (containerized version)
- You will have to create a Docker Image for CData Sync and push it to a docker registry where you will be able to pull from. For more information, have a look at the following CData Community article:
- AWS account
- An active AWS account is required with the necessary permissions to create and manage resources such as EC2, and VPC
- AWS CLI (optional)
- In case you want to define AWS credentials using
aws configurecommand, rather than exporting those as environmental variables
- In case you want to define AWS credentials using
Terraform configurations
This section details the Terraform setup required to automate the deployment of CData Sync on AWS. It covers:
- VPC Module: Defines the networking infrastructure, including subnets, route tables, and internet gateways.
- EC2 Module: Manages the provisioning of EC2 instances where CData Sync will be deployed.
- Parent Module: Orchestrates and integrates the VPC and EC2 modules to ensure seamless deployment.
Each module is structured to ensure scalability, security, and automation, making CData Sync deployment efficient and reproducible.
Below is a breakdown of the directory and file structure:
│── sync/
│ ├── modules/ # Dir containing reusable Terraform
│ │ ├── server/ # Server (EC2) module
│ │ │ ├── docker.sh # Shell script to install Docker
│ │ │ ├── outputs.tf # Outputs for the server module
│ │ │ ├── server.tf # Configuration for the EC2
│ │ │ ├── variables.tf # Input vars for the server
│ │ ├── vpc/ # VPC module
│ │ │ ├── outputs.tf # Outputs for the VPC module
│ │ │ ├── variables.tf # Input variables for the VPC
│ │ │ ├── vpc.tf # Configuration for networking
│ ├── main.tf # Main Terraform configuration file
│ ├── outputs.tf # Global outputs
│ ├── variables.tf # Global input variablest
VPC module
Within the vpc directory of the project, the following Terraform configuration files are configured:
# Fetch the list of availability zones in the current AWS region
data "aws_availability_zones" "available" {}
# Define the VPC
resource "aws_vpc" "main" {
cidr_block = var.vpc_cidr
enable_dns_support = true
enable_dns_hostnames = true
tags = {
Name = var.vpc_name
Environment = "dev"
Terraform = "true"
}
}
# Create Public Subnets
resource "aws_subnet" "public_subnets" {
count = min(var.public_subnet_count, length(data.aws_availability_zones.available.names))
vpc_id = aws_vpc.main.id
cidr_block = cidrsubnet(var.vpc_cidr, 8, count.index + 100)
availability_zone = data.aws_availability_zones.available.names[count.index]
map_public_ip_on_launch = true
tags = {
Name = "alex_tf_public_subnet_${count.index + 1}"
Environment = "dev"
Terraform = "true"
}
}
# Create Private Subnets
resource "aws_subnet" "private_subnets" {
count = min(var.private_subnet_count, length(data.aws_availability_zones.available.names))
vpc_id = aws_vpc.main.id
cidr_block = cidrsubnet(var.vpc_cidr, 8, count.index)
availability_zone = data.aws_availability_zones.available.names[count.index]
tags = {
Name = "alex_tf_private_subnet_${count.index + 1}"
Environment = "dev"
Terraform = "true"
}
}
# Create Internet Gateway
resource "aws_internet_gateway" "igw" {
vpc_id = aws_vpc.main.id
tags = {
Name = "alex_tf_internet_gateway"
Environment = "dev"
Terraform = "true"
}
}
# Create EIP to be associated with the EC2 instance
resource "aws_eip" "cdatasync_eip" {
depends_on = [aws_internet_gateway.igw]
tags = {
Name = "alex_tf_igw_eip"
}
}
# Create Route Table for Public Subnets
resource "aws_route_table" "public" {
vpc_id = aws_vpc.main.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.igw.id
}
tags = {
Name = "alex_tf_public_route_table"
Environment = "dev"
Terraform = "true"
}
}
# Associate Public Subnets with the Public Route Table
resource "aws_route_table_association" "public" {
count = length(aws_subnet.public_subnets)
route_table_id = aws_route_table.public.id
subnet_id = aws_subnet.public_subnets[count.index].id
}
# Create Route Table for Private Subnets
resource "aws_route_table" "private" {
vpc_id = aws_vpc.main.id
tags = {
Name = "alex_tf_private_route_table"
Environment = "dev"
Terraform = "true"
}
}
# Associate Private Subnets with the Private Route Table
resource "aws_route_table_association" "private" {
count = length(aws_subnet.private_subnets)
route_table_id = aws_route_table.private.id
subnet_id = aws_subnet.private_subnets[count.index].id
}vpc.tf configuration file sets up a structured VPC with both public and private subnets across different AZs, ensuring internet access for public resources, while keeping private resources isolated.
# VPC module variables
variable "vpc_cidr" {
description = "The CIDR block for the VPC"
default = "10.0.0.0/16"
}
variable "vpc_name" {
description = "The name of the VPC"
default = "alex-tf-vpc"
}
variable "public_subnet_count" {
description = "Number of public subnets to create"
default = 3
}
variable "private_subnet_count" {
description = "Number of private subnets to create"
default = 3
}Within variables.tf file we define the variables of the module, which provide flexibility in defining the VPC architecture, ensuring scalability while maintaining modularity in Terraform deployments. Variables like vpc_cidr, public_subnet_count, have been defined in this file, while being interpolated to the previous configuration file.
# VPC module outputs
output "vpc_id" {
description = "The ID of the VPC"
value = aws_vpc.main.id
}
output "public_subnet_ids" {
description = "IDs of the public subnets"
value = aws_subnet.public_subnets[*].id
}
output "private_subnet_ids" {
description = "IDs of the private subnets"
value = aws_subnet.private_subnets[*].id
}
output "internet_gateway_id" {
description = "ID of the Internet Gateway"
value = aws_internet_gateway.igw.id
}
output "cdatasync_eip_allocation_id" {
value = aws_eip.cdatasync_eip.id
}
output "cdatasync_eip_address" {
value = aws_eip.cdatasync_eip.public_ip
}
output "aws_availability_zones" {
description = "The availability zones"
value = data.aws_availability_zones.available.names
}outputs.tf file defines Terraform outputs for the VPC module, allowing other modules to reference key resources created within the VPC. The outputs provide essential details about the infrastructure components. This configuration is crucial, as it will enable the invocation of VPC module resources into the parent module, from where the Terraform will get executed and create the state.
EC2 module
Within the server directory of the project, the following Terraform configuration files are configured:
# Lookup Latest Ubuntu 22.04 AMI Image
data "aws_ami" "ubuntu" {
most_recent = true
filter {
name = "name"
values = ["ubuntu/images/hvm-ssd/ubuntu-jammy-22.04-amd64-server-*"]
}
filter {
name = "virtualization-type"
values = ["hvm"]
}
owners = ["099720109477"]
}
# Build EC2 instance in Public Subnet
resource "aws_instance" "cdatasync_ubuntu" {
ami = data.aws_ami.ubuntu.id
instance_type = var.instance_type
subnet_id = var.subnet_id
security_groups = [aws_security_group.sync_sg.id]
associate_public_ip_address = true
key_name = aws_key_pair.generated.key_name
connection {
user = "ubuntu"
private_key = tls_private_key.generated.private_key_pem
host = self.public_ip
}
provisioner "local-exec" {
command = "chmod 600 ${local_file.private_key_pem.filename}"
}
# Upload the docker.sh file
provisioner "file" {
source = "${path.module}/docker.sh"
destination = "/tmp/docker.sh"
}
# Run the docker.sh file using remote-exec
provisioner "remote-exec" {
inline = [
"chmod +x /tmp/docker.sh",
"sudo /tmp/docker.sh",
"sudo docker container run -d -p 8181:8181 --name cdatasync -v syncvolume:/var/opt/sync aleksanderp01/cdata-sync:latest"
]
}
tags = {
Name = "CData Sync Terraform EC2 Server"
}
lifecycle {
ignore_changes = [security_groups]
}
}
# Associate Elastic IP with EC2 Instance
resource "aws_eip_association" "ec2_eip" {
instance_id = aws_instance.cdatasync_ubuntu.id
allocation_id = var.eip_allocation_id
}
# Create Security Group to allow SSH, HTTP, HTTPS, and CData Sync traffic
resource "aws_security_group" "sync_sg" {
name = "alex-terraform-sg"
description = "Security group for web servers allowing SSH, HTTP, and HTTPS access, created with Terraform"
vpc_id = var.vpc_id
ingress {
description = "Allow SSH access"
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
description = "Allow HTTP access"
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
description = "Allow HTTPS access"
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
description = "Allow access to CData Sync"
from_port = 8181
to_port = 8181
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
description = "Allow all outbound traffic"
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
# Generate SSH Key Pair for EC2 Instance
resource "aws_key_pair" "generated" {
key_name = "AlexTFKey"
public_key = tls_private_key.generated.public_key_openssh
}
resource "tls_private_key" "generated" {
algorithm = "RSA"
}
resource "local_file" "private_key_pem" {
content = tls_private_key.generated.private_key_pem
filename = "AlexTFKey.pem"
}server.tf configuration file automates the deployment of an Ubuntu-based EC2 instance with a dockerized CData Sync. It ensures the instance is publicly accessible via SSH, web protocols, and the CData Sync service. The setup also enforces security best practices with a dedicated security group and an SSH key pair created locally and uploaded to AWS.
# EC2 module variables
variable "instance_type" {
description = "The type of the EC2 instance"
type = string
default = "t3.large"
}
variable "subnet_id" {
description = "Public subnet id where the EC2 instance will be deployed"
type = string
}
variable "vpc_id" {
description = "VPC id where the EC2 instance will be deployed"
type = string
}
variable "eip_allocation_id" {
description = "Elastic IP allocation id to associate with the EC2 instance"
type = string
}variables.tf configuration file defines input variables for configuring an EC2 instance. These variables allow for flexible and reusable deployments by parameterizing key properties of the EC2 instance (allowing users to customize instance type, networking, and IP settings without modifying the core infrastructure code).
Parent module
Within the root directory of the project, the following Terraform configuration files are configured:
# Configure AWS Provider
provider "aws" {
region = var.aws_region
}
# Invoke VPC module
module "vpc" {
source = "./modules/vpc"
}
# Invoke Server module
module "server" {
source = "./modules/server"
subnet_id = element(module.vpc.public_subnet_ids, 0)
vpc_id = module.vpc.vpc_id
eip_allocation_id = module.vpc.cdatasync_eip_allocation_id
}main.tf configuration file modularizes infrastructure by separating networking (VPC module) from compute resources (EC2 module).
It enables reusability and scalability, as each module can be modified independently. It also improves flexible deployment, as users can change AWS regions or subnet allocation without modifying core infrastructure code.
# Global variables
variable "aws_region" {
type = string
default = "eu-north-1"
}
variable "sync_port" {
type = number
default = 8181
}variables.tf configuration file defines global variables to ensure flexibility and maintainability in the infrastructure deployment (allowing AWS Region or CData Sync port modifications without affecting core infrastructure logic).
# Global outputs
output "cdatasync_ui_access" {
value= "You can access CData Sync at http://${module.vpc.cdatasync_eip_address}:${var.sync_port}"
}outputs.tf configuration file in this module defines a global output that provides an easily accessible URL for the CData Sync web interface, once the Terraform operation succeeds.
DEMO: CData Sync automatic deployment on AWS
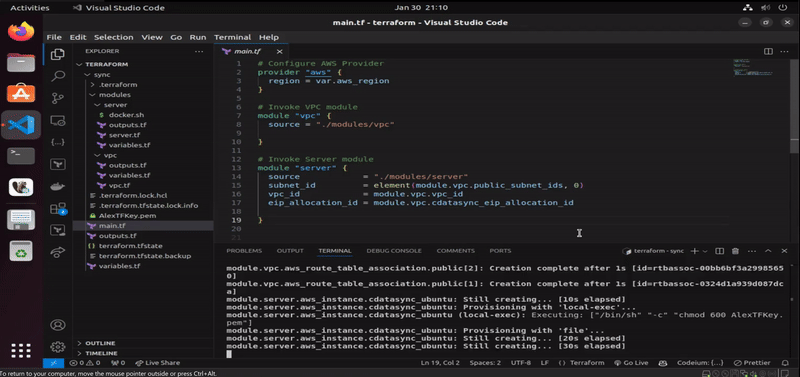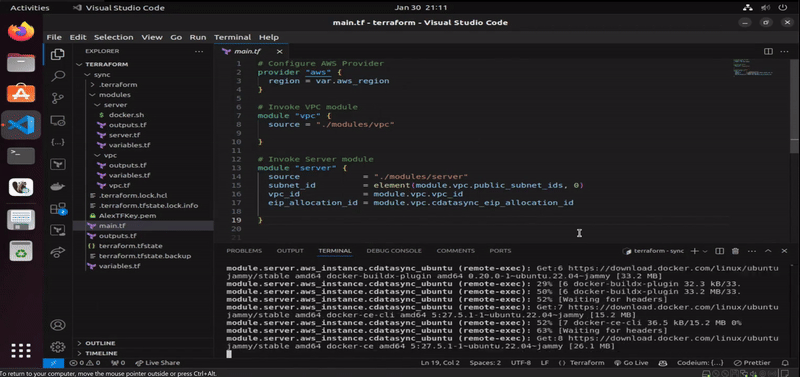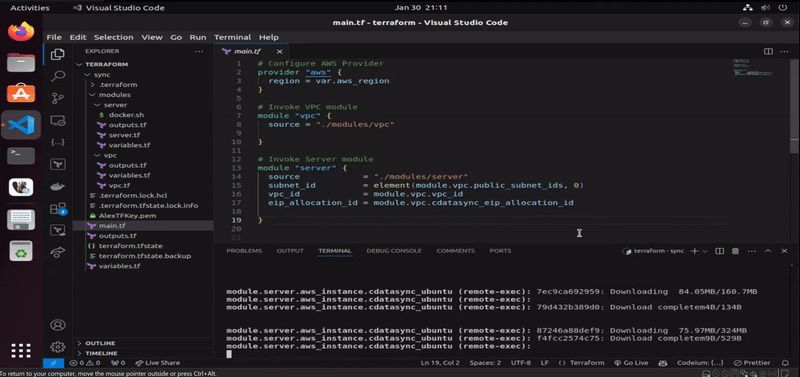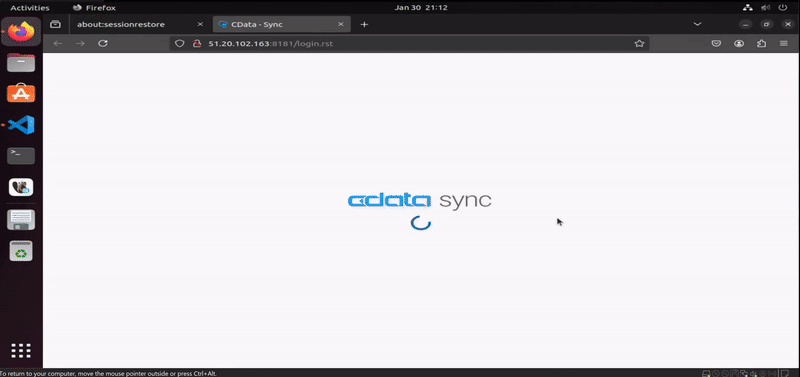
This section visualizes the successful automated deployment of CData Sync on AWS via Terraform. Once the directory is initialized and the required providers are downloaded (via terraform init command), we start by checking the existing state between configured resources and the cloud provider (via terraform plan command). Since we are starting from scratch, Terraform is notifying us that after the plan execution, a total of 23 resources will be created on the infrastructure (once we run terraform apply command). We can inspect that resources are stating to get created (starting with the networking, deployment of the EC2 instance, as well as SSH connectivity into it).
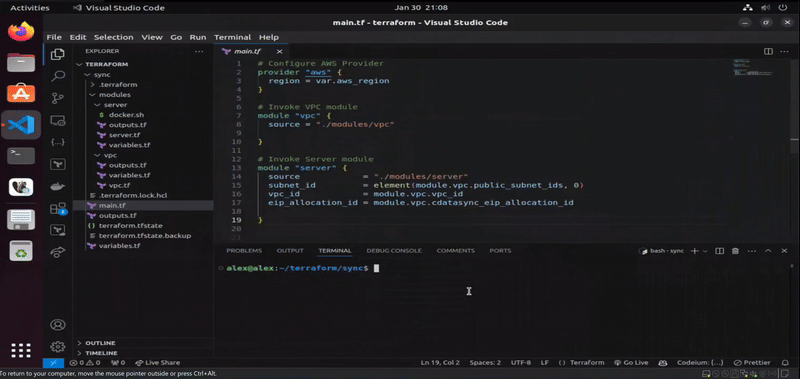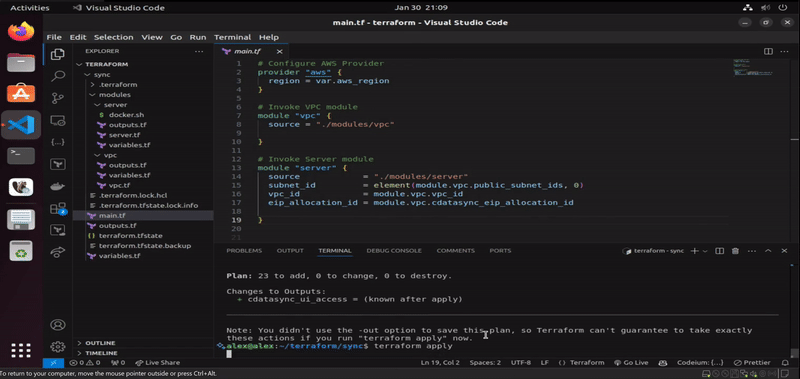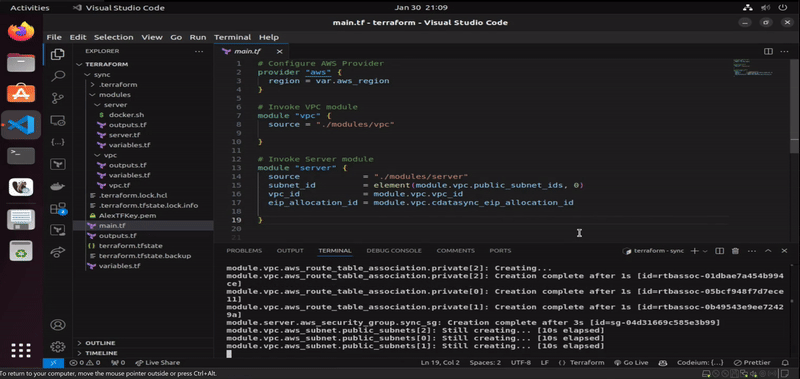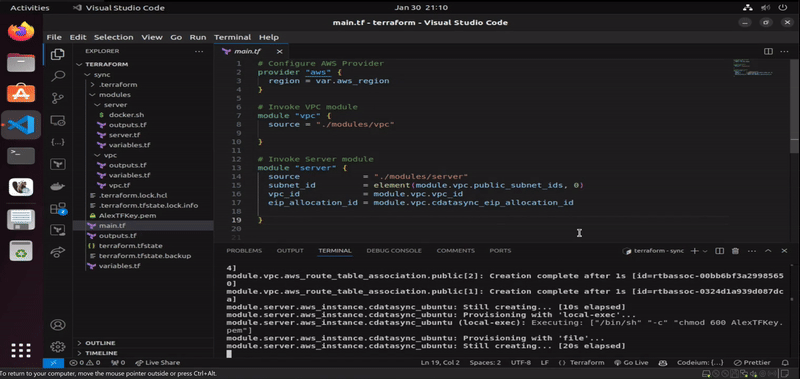
Once AWS resources are fully deployed, and that we have been connected remotely to the EC2 instance via remote-exec provisioner, the next step is to upload docker.sh file using file provisioner of Terraform, which will handle the installation of Docker. When Docker gets successfully installed, the operation proceed with the deployment of dockerized CData Sync from Docker Hub via the last remote-exec provisioner in the configuration of the EC2 module in Terraform. When the operation finishes, the configured output of root module displays where we can access the newly-created instance of CData Sync.
Conclusions
This article successfully demonstrated the automatic deployment of CData Sync on AWS using Terraform, transforming manual workflows into scalable and modern infrastructure-as-code (IaC) architecture. A key takeaway was Terraform’s ability to enforce reproducibility, reducing human error through declarative code. Moving forward, embedding CI/CD pipelines and performance monitoring (e.g., CloudWatch) could further accelerate deployment cycles and operational resilience.
Looking ahead, the framework can be extended to future-proof the architecture:
- Multi-Cloud Flexibility: The Terraform codebase can be adapted for Azure or GCP with minimal refactoring, leveraging provider-specific modules (e.g., Azure VMs, Google Cloud Storage) to avoid vendor lock-in.
- Hybrid Cloud/On-Premises: By integrating the Proxmox Provider for Terraform, the same IaC principles can deploy CData Sync to on-premises virtualized environments, enabling hybrid cloud strategies for compliance-sensitive or cost-conscious organizations.
This adaptability ensures the solution remains relevant as infrastructure needs evolve, whether scaling across clouds or balancing cloud-native and legacy systems.
Key Considerations
For teams replicating this workflow, security and cost governance must anchor the design. Credentials should never be hardcoded in Terraform configuration files (instead define those as environment variables either locally or migrate to HCP Terraform Cloud). Although the state file will always keep sensitive information as visible, make sure to utilize a remote backend storage (where the state and the rest of providers are stored) that encrypts the data at rest (i.e. ‘s3’ remote backend). In order to enforce PoLP (Principle of Least Privilege), make sure to create custom IAM Roles and attach the sufficient privileges to the IAM User for accomplishing the tasks of this article. In addition, reliability hinges on pre-deployment staging tests and Terraform state locking (S3 + DynamoDB) to avoid conflicts (in case 2 or more users update Terraform state at the same time, you should consider state locking feature). Finally, in terms of State Management, for multi-cloud deployments centralize Terraform state in a cloud-agnostic storage system (e.g., HashiCorp Consul) to avoid fragmentation.
