

Why is Data Quality Important?
In enterprise environments, data quality directly impacts operational efficiency, regulatory compliance, and decision-making. Poor-quality data can lead to inaccurate reports, financial losses, and wasted resources. Data engineers play a critical role in ensuring that data remains accurate, consistent, and reliable.
How CData Virtuality Helps with Data Quality Assurance
CData Virtuality provides a virtualized data integration layer that allows organizations to query and analyze data from multiple sources in real time. Instead of replicating data, it offers centralized access, enabling engineers to apply quality checks and transformations without altering the original sources. Key advantages include:
- Real-time metadata querying to understand schema consistency.
- Automated data validation rules to prevent incorrect entries.
- Data governance controls to manage access and security.
- Integration capabilities with DataSpot and other data governance and quality monitoring systems.
Key Aspects of Data Quality
Ensuring data quality involves multiple dimensions:
1. Completeness – No critical data should be missing.
2. Accuracy – Values should be correct and reflect reality.
3. Consistency – Data should be uniform across different sources.
4. Uniqueness – Duplicates should be identified and removed.
5. Timeliness – Data should be up-to-date and refreshed as needed.
6. Data Governance – Access permissions and compliance rules should be enforced.
Using CData Virtuality to Check and Validate Data
Identifying Missing or Incomplete Data
Missing data can indicate an issue with data ingestion or transformation pipelines. Engineers can use INFORMATION_SCHEMA to identify nullable fields:
SELECT TABLE_NAME, COLUMN_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE IS_NULLABLE = 'YES';
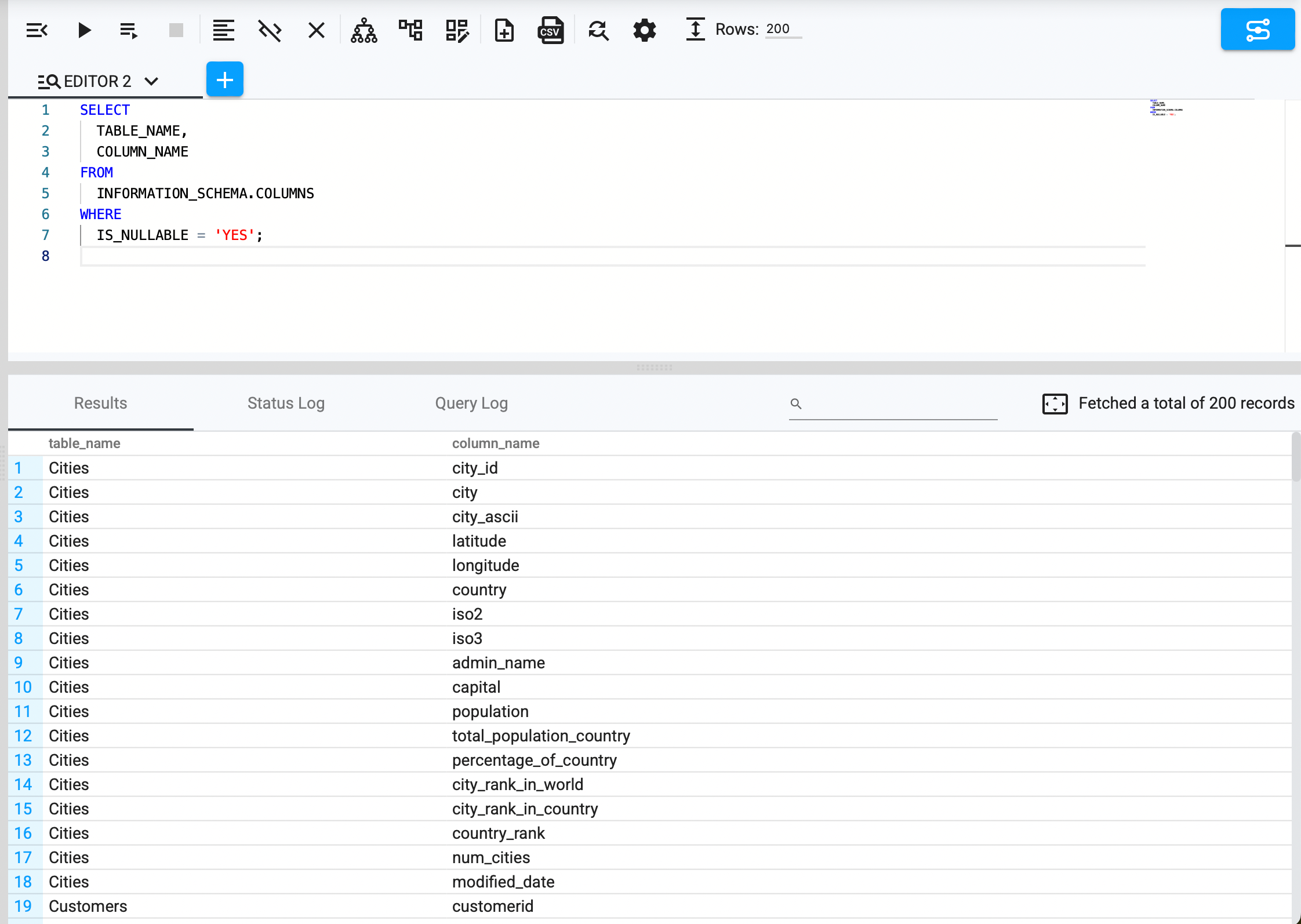
Example Use Case:
A retail company using CData Virtuality to consolidate sales data from multiple regions can run this query to identify if critical fields like product_price or customer_id allow `NULL` values, which could indicate a schema inconsistency.
SELECT * FROM sales_data WHERE customer_id IS NULL OR product_price IS NULL;
Detecting Data Anomalies and Outliers
Outliers can distort business insights, leading to incorrect conclusions. Detect anomalies in numeric data using average and standard deviation:
SELECT customerid, AVG(total) AS avg_price, STDDEV_POP(total) AS price_variability
FROM postgres.Orders
GROUP BY customerid;
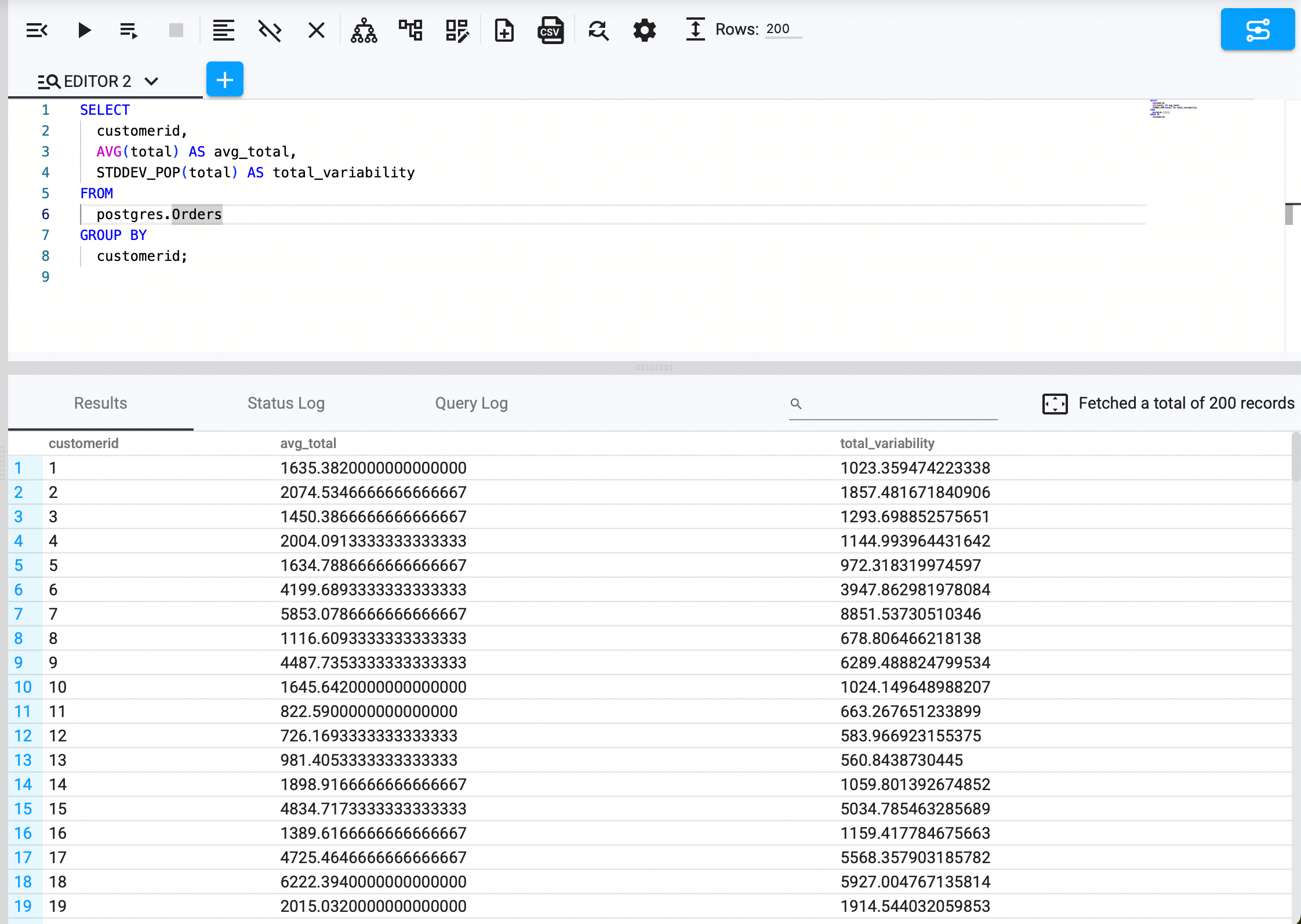
Example Use Case:
A financial institution analyzing transaction data may find that a particular region’s sales prices deviate significantly from the average, indicating either an input error or fraud.
To detect extreme values:
SELECT orderid, orderdate, total
FROM postgres.Orders
WHERE total > (SELECT AVG(total) * 3 FROM postgres.Orders);
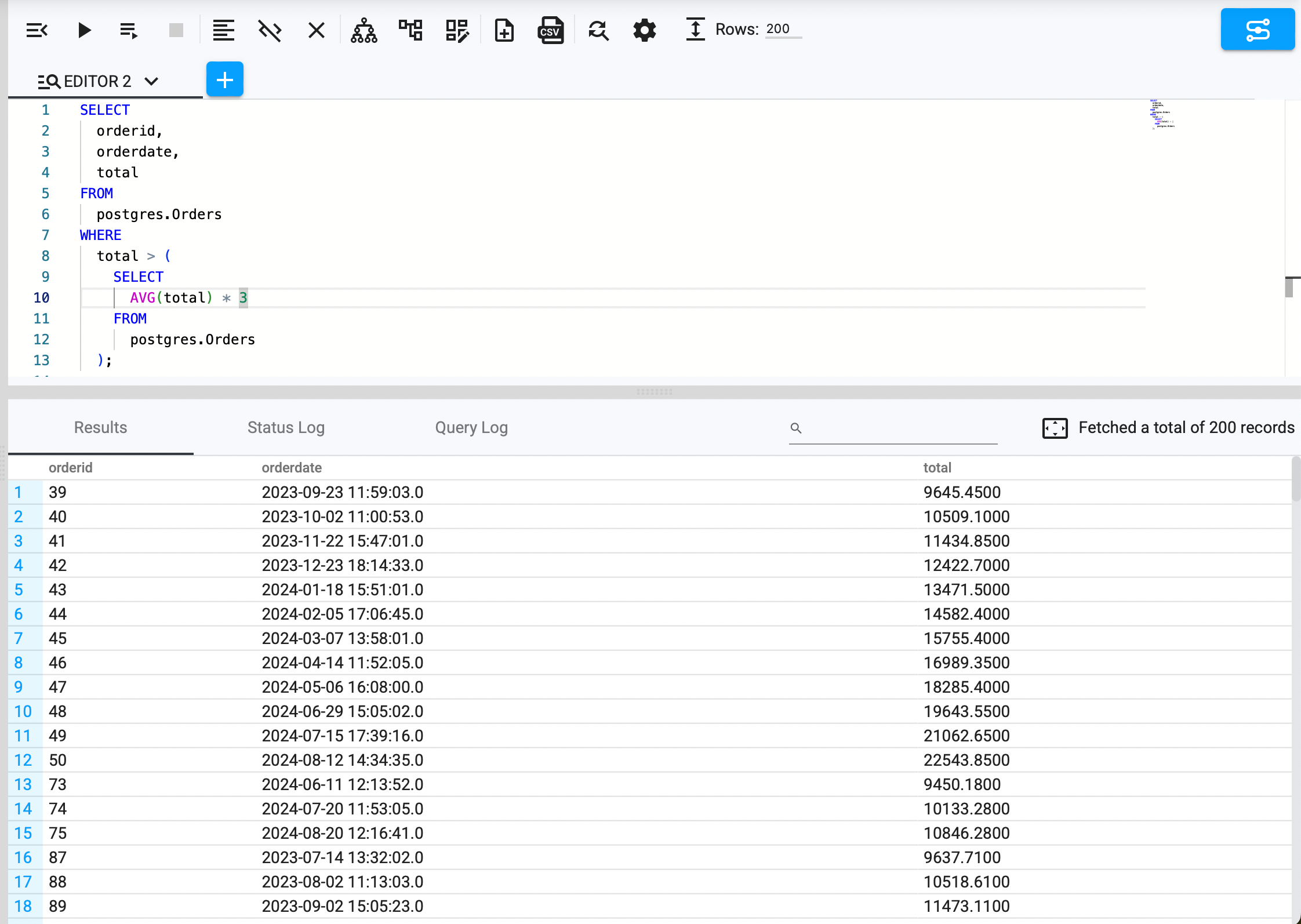
Validating Data Consistency Across Sources
In enterprise environments, data is often stored across different systems. Engineers can compare values to ensure consistency between two sources:
SELECT
source1.orderid,
source1.total AS source1_amount,
source2.total AS source2_amount
FROM
postgres.Orders AS source1
FULL OUTER JOIN mysql.Orders AS source2 ON source1.orderid = source2.orderid
WHERE
source1.total <> source2.total
OR source1.total IS NULL
OR source2.total IS NULL;
Example Use Case:
A multinational e-commerce company integrates SAP and Salesforce through CData Virtuality. This query helps them validate whether the order amounts stored in both systems match.
Profiling Data to Identify Common Errors
Data profiling provides insights into column-level statistics to detect unexpected duplicates, missing values, or incorrect formats:
SELECT companyname, COUNT(DISTINCT companyname) AS unique_values,
MIN(companyname) AS min_value, MAX(companyname) AS max_value
FROM postgres.Customers
GROUP BY companyname;
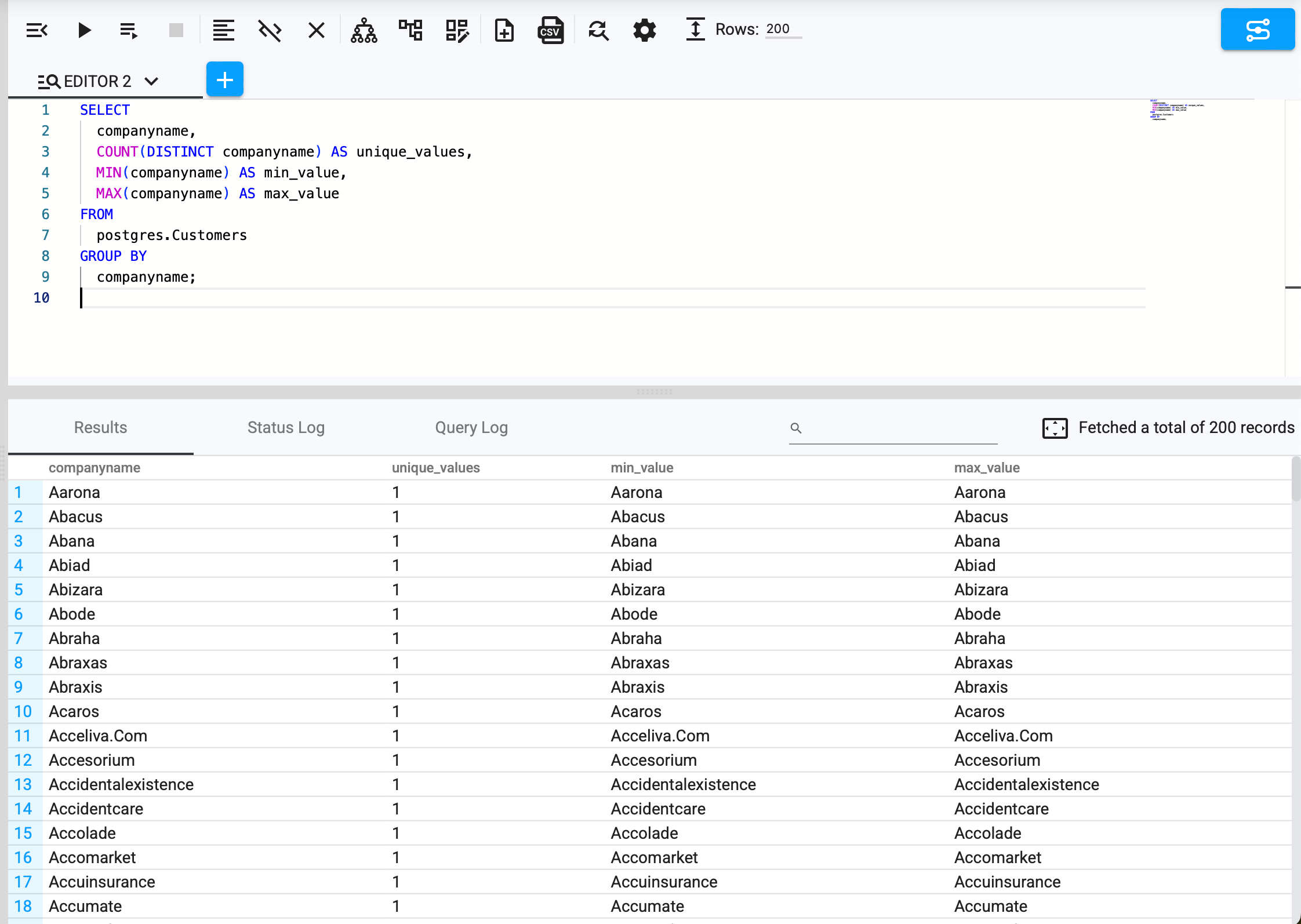
Example Use Case:
A telecom provider assessing customer subscription data might use this query to determine if phone numbers follow a valid pattern.
Applying Business Rules for Data Validation
CData Virtuality allows engineers to create virtual views that enforce business rules dynamically without altering the raw data.
CREATE VIEW validated_orders AS
SELECT orderid, customerid,
CASE
WHEN total < 0 THEN NULL
ELSE total
END AS valid_total
FROM postgres.Orders;
Example Use Case:
A B2B supply chain platform can use this view to prevent processing of orders with negative values, ensuring data accuracy.
Automating Data Quality Checks
Data engineers can automate quality checks using scheduled jobs and alerts.
Setting Up Automated Data Quality Jobs
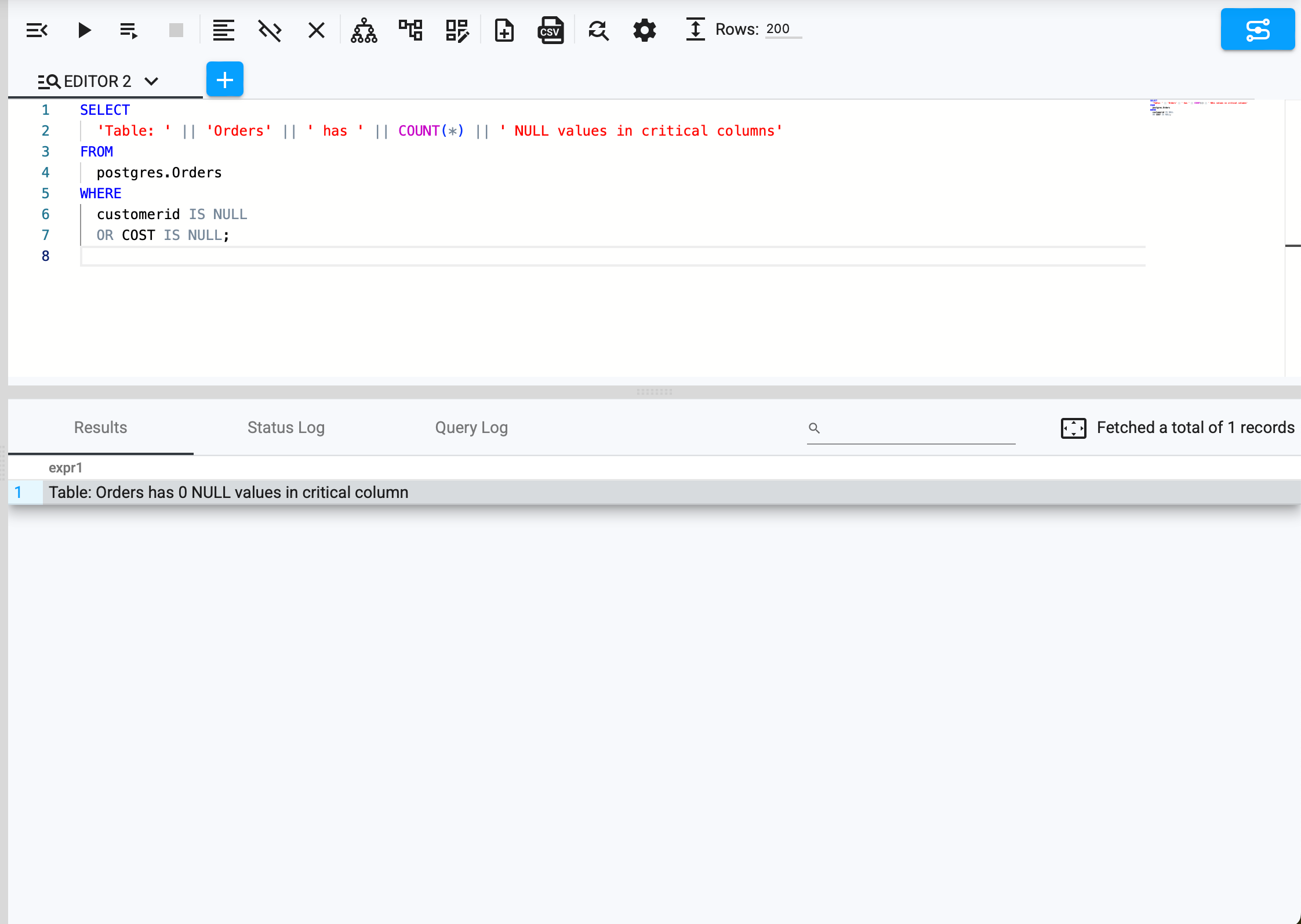
Run periodic checks using a scheduled query:
SELECT 'Table: ' || 'Orders' || ' has ' || COUNT(*) || ' NULL values in critical columns'
FROM postgres.Orders
WHERE customerid IS NULL OR COST IS NULL;
A logging mechanism can be added to capture issues:
INSERT INTO
error_log (error_message, TIMESTAMP)
SELECT
'Missing data detected in sales_data',
NOW()
FROM
sales_data
WHERE
customer_id IS NULL;
Integrating with External Systems (e.g., DataSpot)
To enhance data quality monitoring, CData Virtuality can integrate with DataSpot, an enterprise data governance platform. CData Virtuality’s DataSpot connector allows automated upload and sync of metadata, including information about all of the data sources, tables, columns, data types, virtual views as well as full data lineage information. In this example, we are only using the Data Quality upload features.
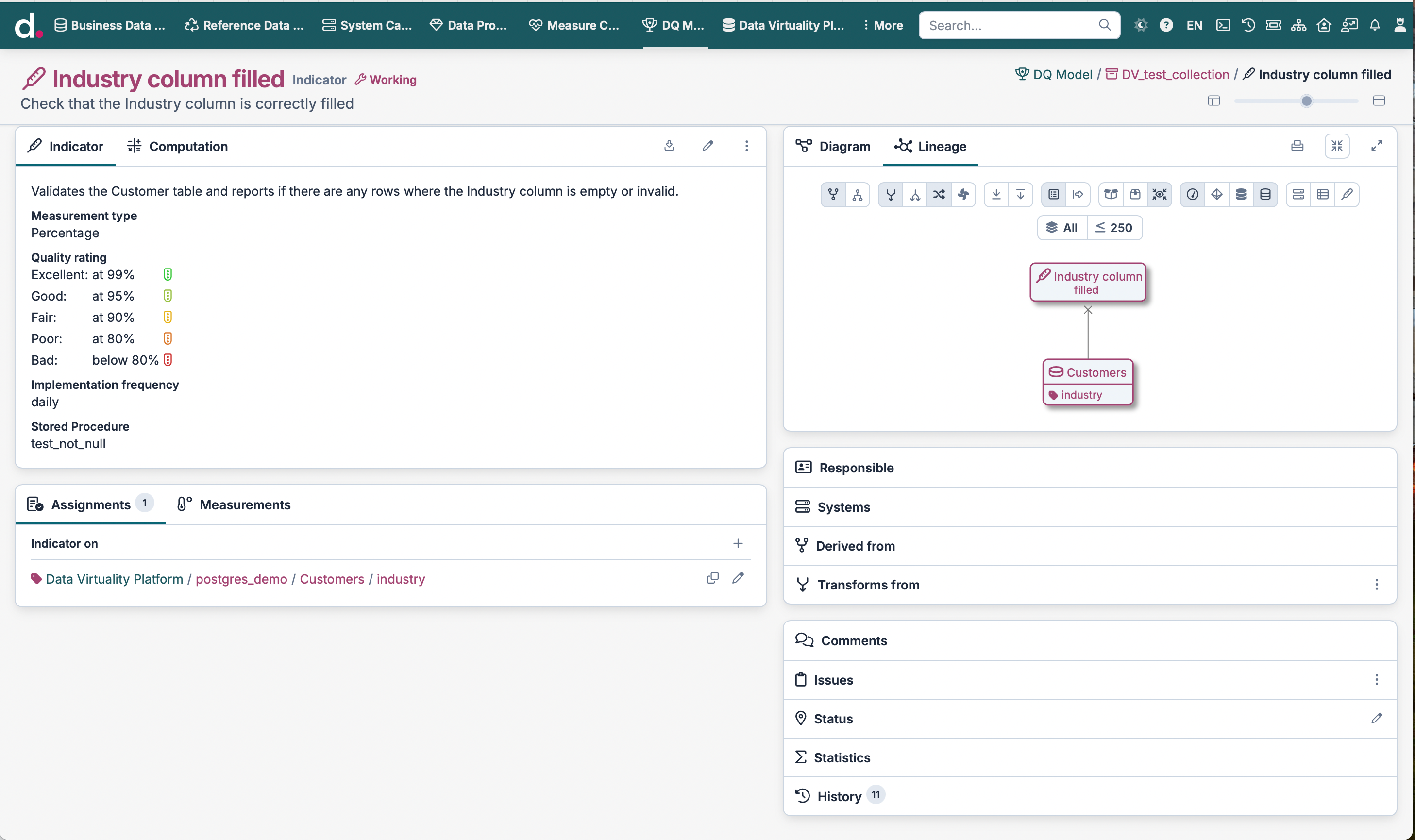
Expose Data Quality Metrics as a Virtual Table
Dataspot expects data quality measurements to be uploaded as JSON and containing certain attributes such as data quality indicator name, exact time when quality was measured and the measurement results.
The easiest way to provide this is by creating a Virtual view with these exact values.
CREATE OR REPLACE VIEW DQ."Industry column filled" AS
-- Reports the number of rows where "Industry" exists and is not null
SELECT 'Industry column filled' as observationOf,
TimestampDiff(SQL_TSI_SECOND, from_unixtime(0) , Now()) * 1000 as dateObserved,
'/CData Virtuality Platform/postgresdemo/Customers' as computedOn,
(SELECT COUNT(*) FROM "postgres.Customers" WHERE "industry" IS NOT NULL) as amountValue,
COUNT(*) as totalCount
FROM postgres.Customers;;
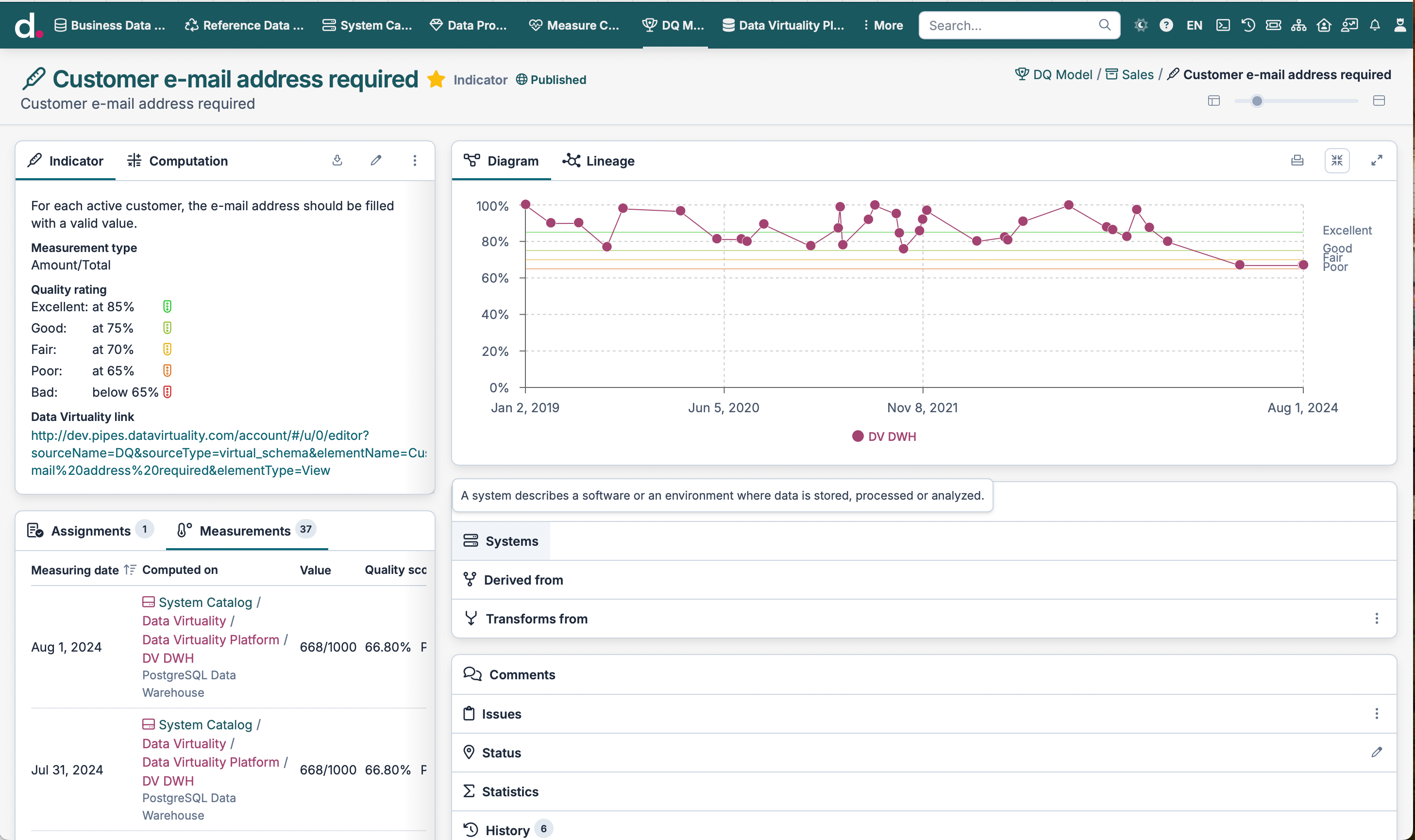
Upload the DQ measurement results to DataSpot
To calculate the new data quality results and automatically upload them to Dataspot, we invoke the upload procedure passing it the name of the virtual view we prepared earlier.
CALL DQ.upload (
"testName" => 'Industry column filled' /* Mandatory */
);
Conclusion: Ensuring Reliable and High-Quality Data in CData Virtuality
Maintaining data quality is essential for enterprises that rely on virtualized data integration. CData Virtuality provides robust tools to help data engineers identify inconsistencies, detect anomalies, validate accuracy, and enforce business rules—all without modifying raw data sources.
Next Steps
- Make use of CData Virtuality’s powerful Jobs and Schedules management to Implement scheduled data validation queries and automate DQ checks.
- Integrate automated error detection and logging to track recurring issues. Consider making use of Notification procedures to send email or Slack notifications in order to catch data quality issues in a timely manner.
- Integrate with dedicated 3rd party tools or use REST API capabilities of CData Virtuality to set up real-time dashboards for data monitoring to proactively catch data quality problems before they propagate.
By applying these strategies, data engineers can establish trust in enterprise data, minimize data integrity risks, and ensure that all analytics and business decisions are based on accurate, complete, and high-quality information.
