

Introduction
One of the often overlooked features of CData Virtuality is the fact that it contains a complete and ready to use metadata repository containing all of the tables, views, columns and data types for all of the connected data sources as well as the virtual views created in the semantic model. These are all available as a set of ANSI-standard read-only views that are updated with every change in the underlying sources and always return the latest state. It provides a structured way to retrieve important information about your data sources without needing to manually inspect each schema.
The columns view contains information about all table and view columns in the data sources configured in the CData Virtuality Server. The tables view contains information about all of the tables, and views contains information about virtual views created in CData Virtuality server.
Why Use the INFORMATION_SCHEMA?
Using the INFORMATION_SCHEMA enables users to:
- Retrieve metadata dynamically instead of relying on manual documentation.
- Audit and document schema structures.
- Debug and analyze data models.
- Optimize performance by reviewing indexes and constraints.
Common Use Cases
- Listing all available tables and views.
- Checking column data types and constraints.
- Understanding relationships between tables.
- Reviewing indexes and stored procedures.
- Automation: e.g. create a replication job for all tables in some schema
Querying the Information Schema
Here are just a few examples of simple but useful use cases for retrieving information from the Information Schema.
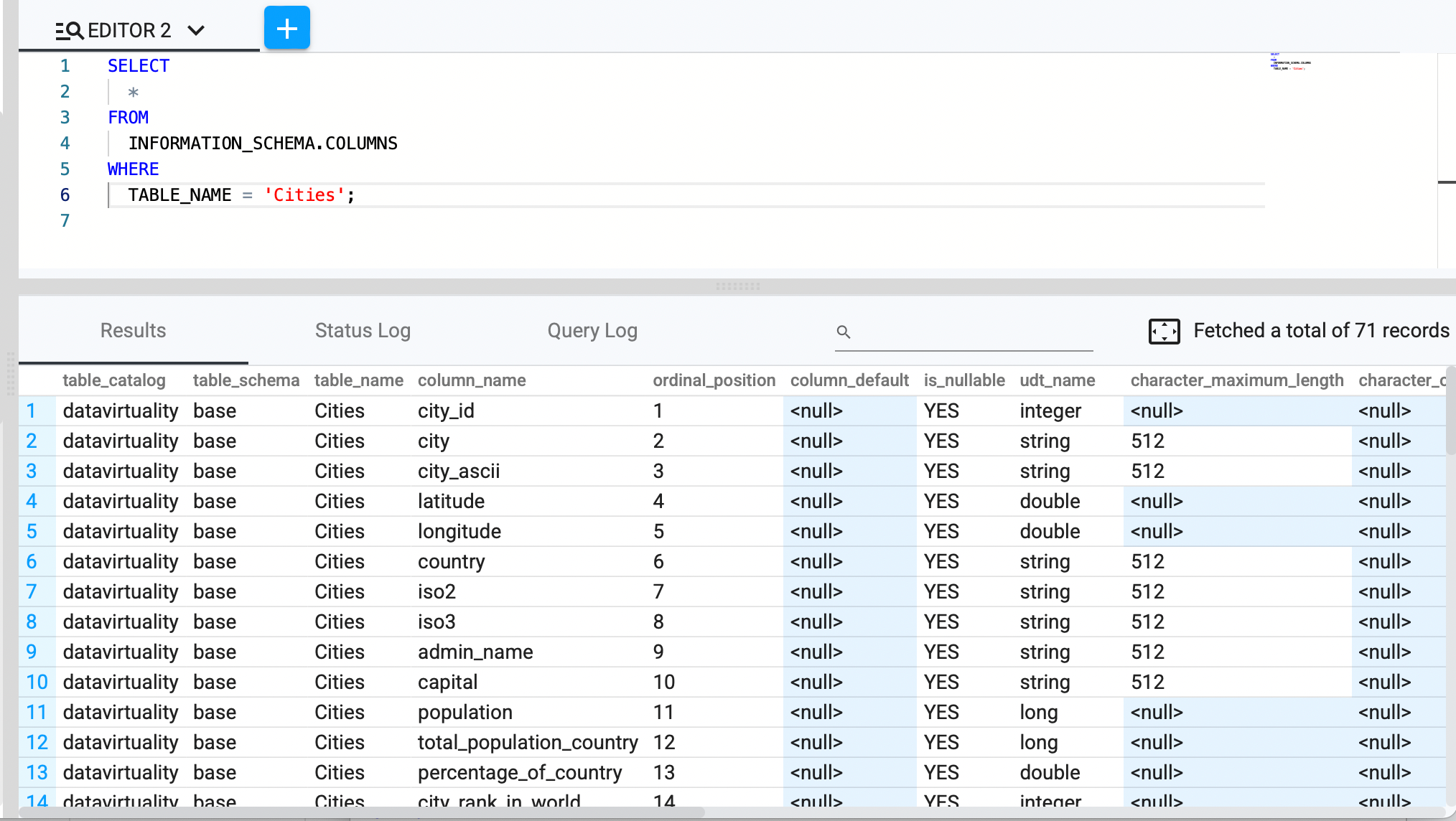
Get all columns of a specific table
SELECT * FROM INFORMATION_SCHEMA.columns
WHERE table_name = 'your_table_name';
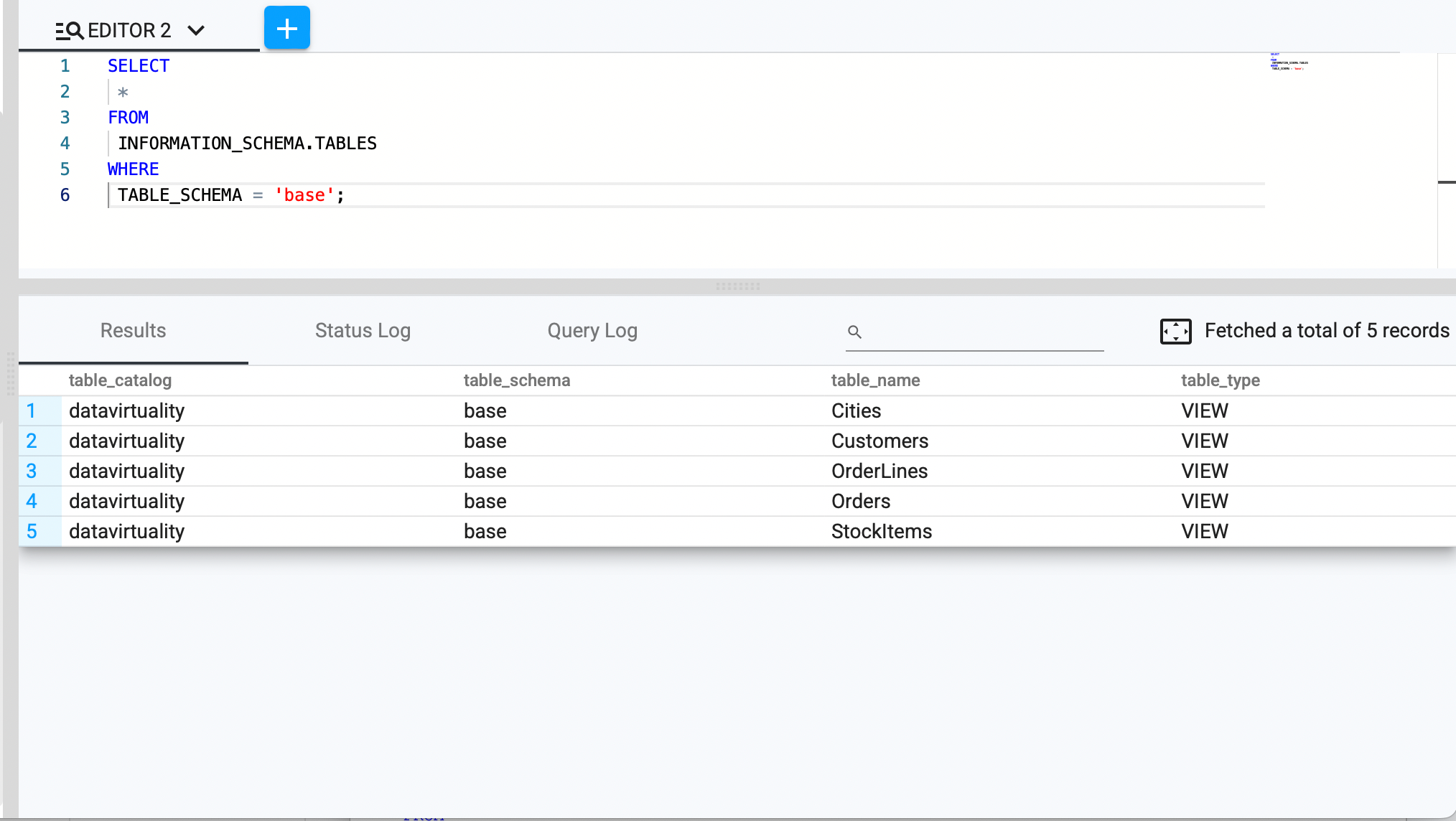
Find all tables in a specific schema
SELECT * FROM INFORMATION_SCHEMA.tables
WHERE table_schema = 'your_schema_name';
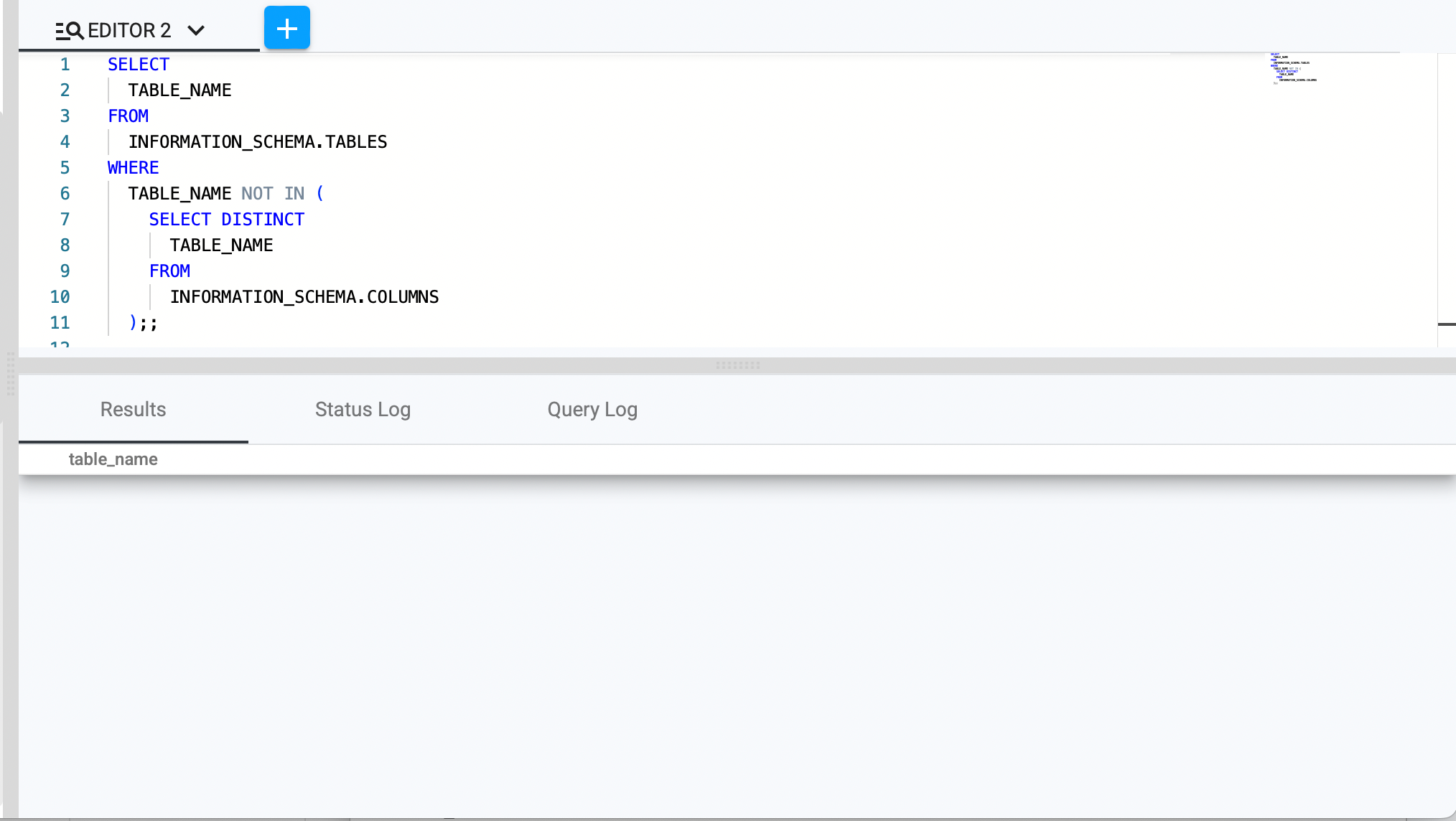
Identify Tables Without Columns
SELECT table_name FROM INFORMATION_SCHEMA.tables
WHERE table_name NOT IN (
SELECT DISTINCT table_name
FROM INFORMATION_SCHEMA.columns
);;
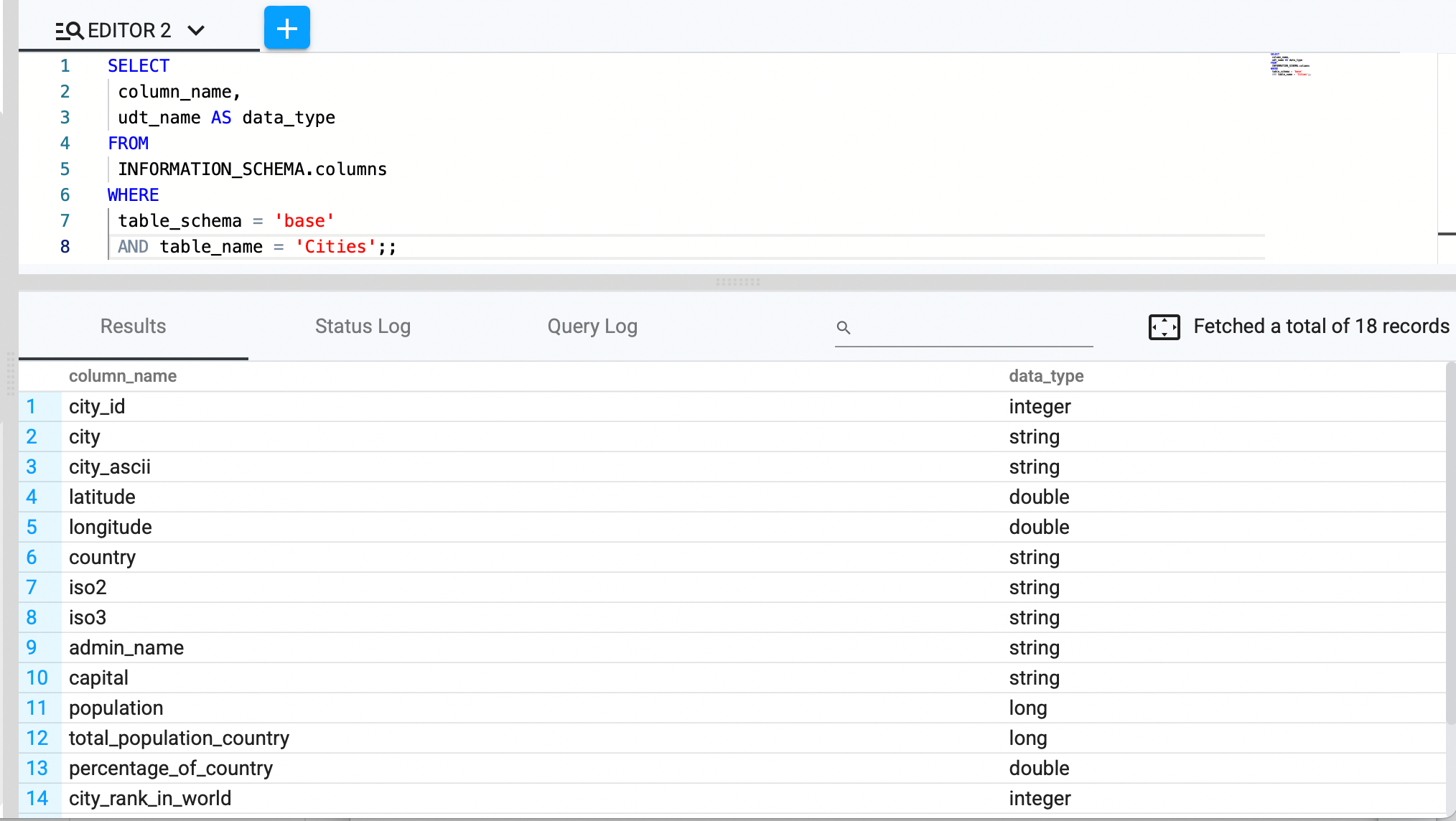
Retrieve All Column Data Types for a Specific Table
SELECT column_name, udt_name AS data_type
FROM INFORMATION_SCHEMA.columns
WHERE table_schema = 'your_schema_name'
AND table_name = 'your_table_name';;
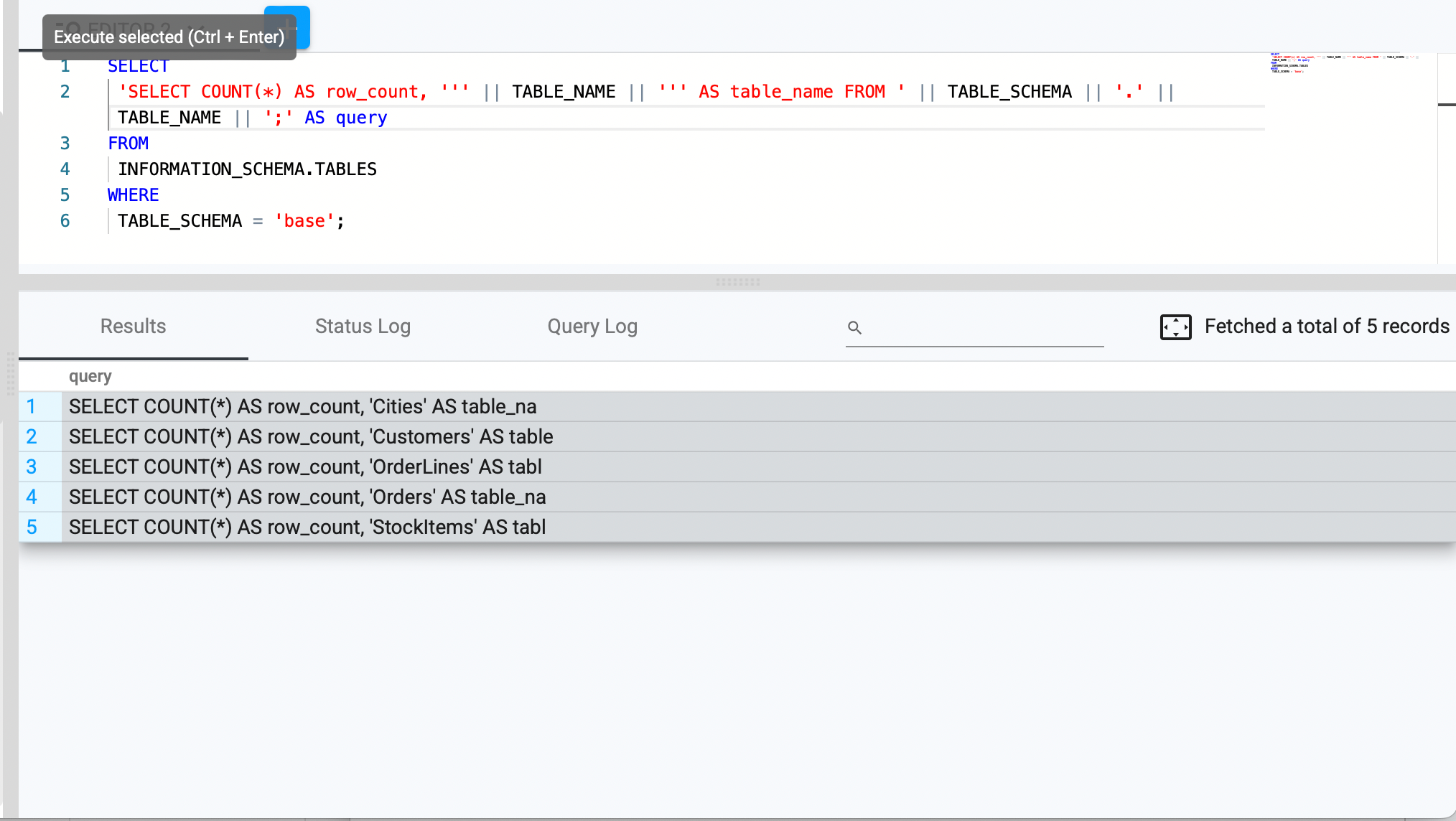
Generate Dynamic SQL for Auditing Table Changes
SELECT
'SELECT COUNT(*) AS row_count, ''' || table_name || ''' AS table_name FROM ' || table_schema || '.' || table_name || ';'
FROM INFORMATION_SCHEMA.tables
WHERE table_schema = 'your_table_name';
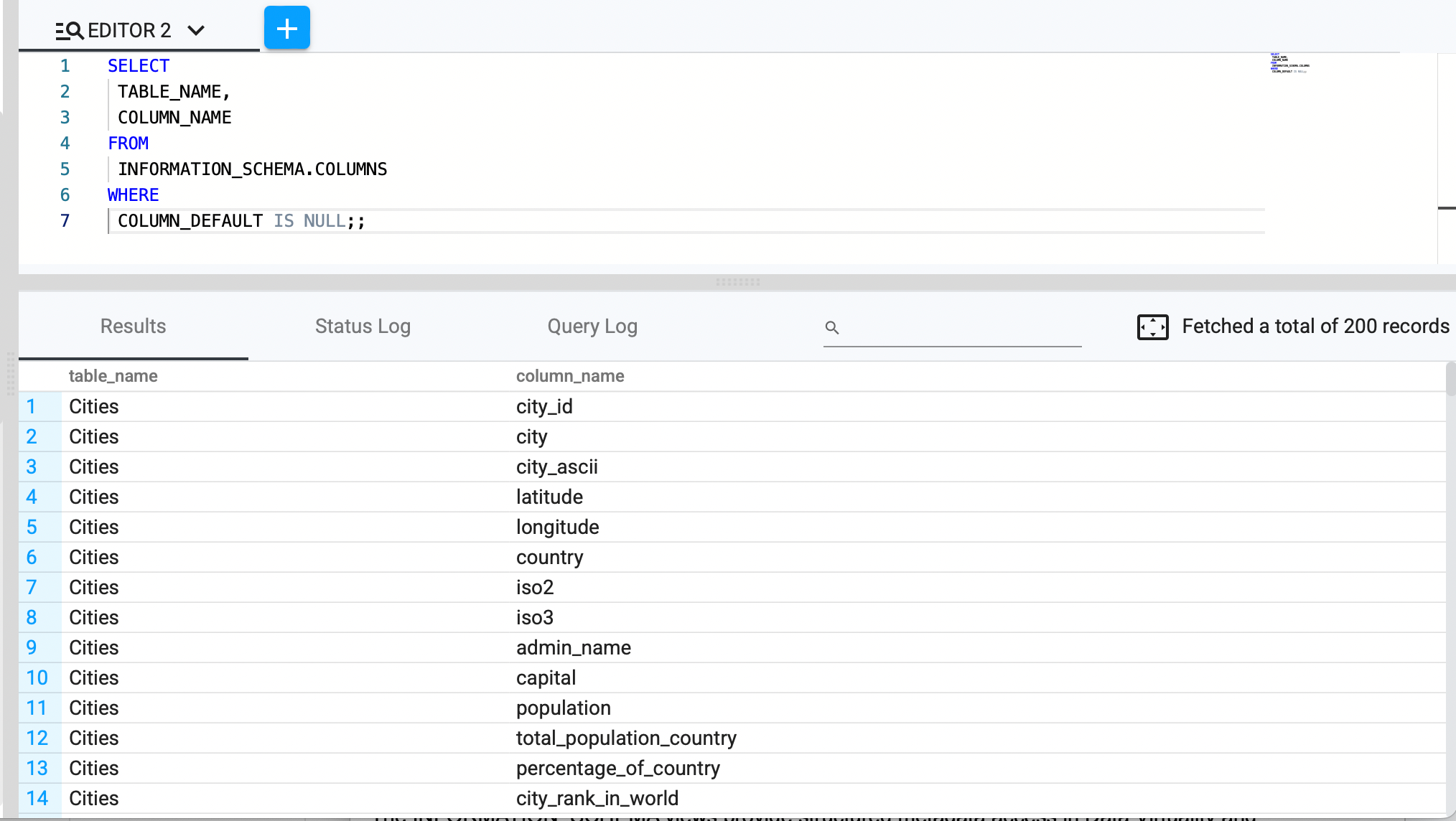
Identify Columns With No Default Value
SELECT table_name, column_name
FROM INFORMATION_SCHEMA.columns
WHERE column_default IS NULL;;
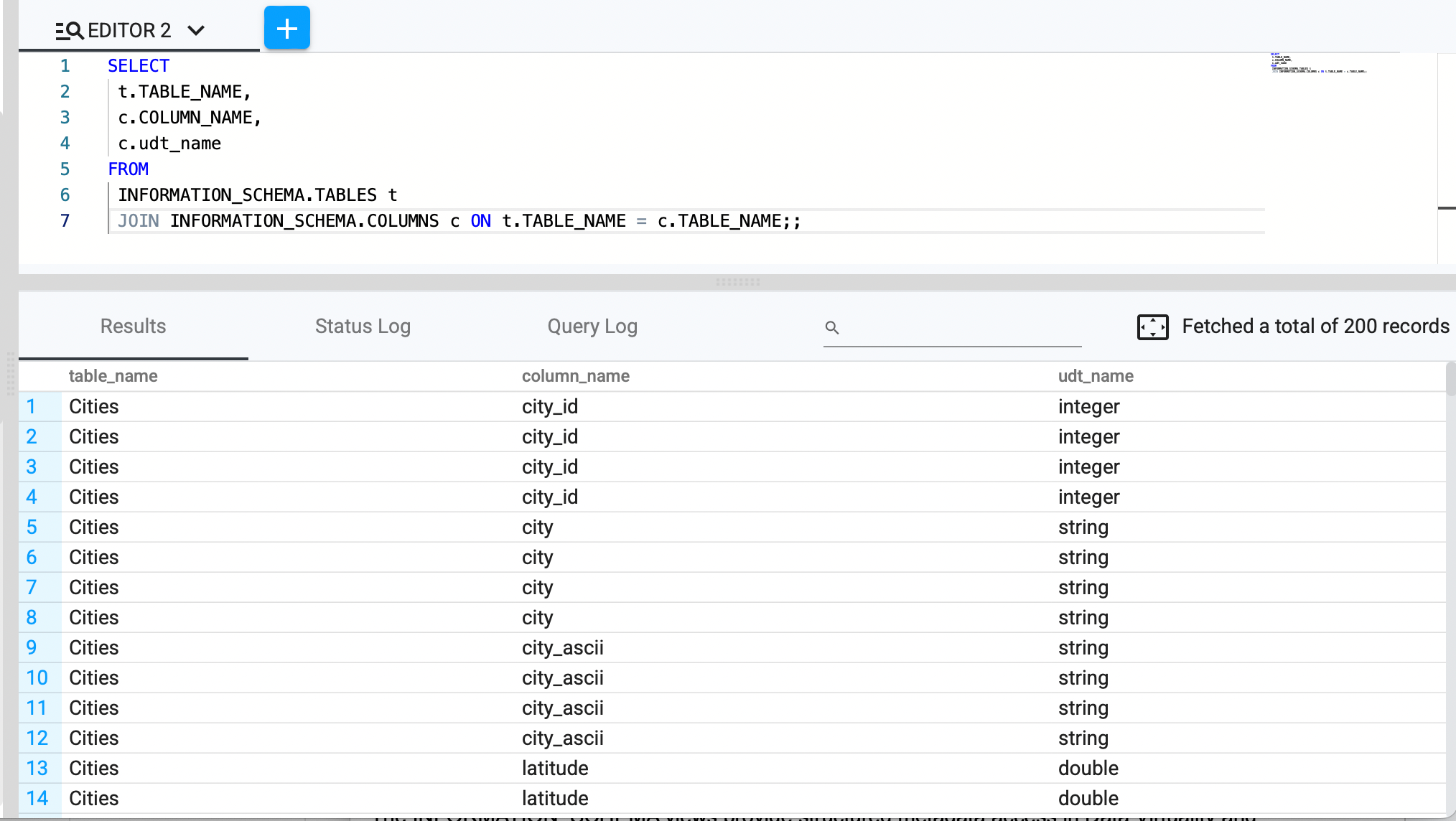
Retrieve all tables along with their column details
SELECT t.table_name, c.column_name, c.udt_name
FROM
INFORMATION_SCHEMA.tables t JOIN INFORMATION_SCHEMA.columns c
ON t.table_name = c.table_name;;
Conclusion
The INFORMATION_SCHEMA views provide structured metadata access in Data Virtuality and querying this metadata simplifies debugging, schema management, and performance optimisation. You can integrate metadata queries into your workflows and make use of dynamic queries as well as the advanced programming options using virtual procedures in CData Virtuality to streamline and automate data catalog creation, change detection and management and many other aspects of your data management.
To find out more about Information Schema, please visit our official documentation page.
