

This is a simple guide on connecting with an OAuth data source in Azure Databricks via the JDBC driver (CData JDBC Driver for Salesforce is used as an example). For a comprehensive guide on utilizing the CData JDBC driver in Azure Databricks, please refer to our Knowledge Base article linked here: Process & Analyze Salesforce Data in Azure Databricks (cdata.com)
To configure the driver to use OAuth from Databricks, you should first generate the OAuthSettings.txt file on a device that supports an internet browser by using the headless machine method. This is touched on in the driver’s documentation, in “Establishing a Connection” section and “Headless Machines” subsection (it is recommended to use “Option 2: Transfer OAuth Settings”): https://cdn.cdata.com/help/RFJ/jdbc/pg_connectionj.htm#headless-machines:~:text=it%20has%20expired.-,Headless%20Machines,-To%20configure%20the
After generating the OAuthSetings.txt file, you will need to upload it to a valid path in Databricks. You can use the FileStore folder within DBFS. To obtain the file path of the uploaded file in Databricks (required for the OAuthSettingsLocation property), click on the triangle icon of the OAuthSettings.txt file > select Copy path > copy File API Format path:
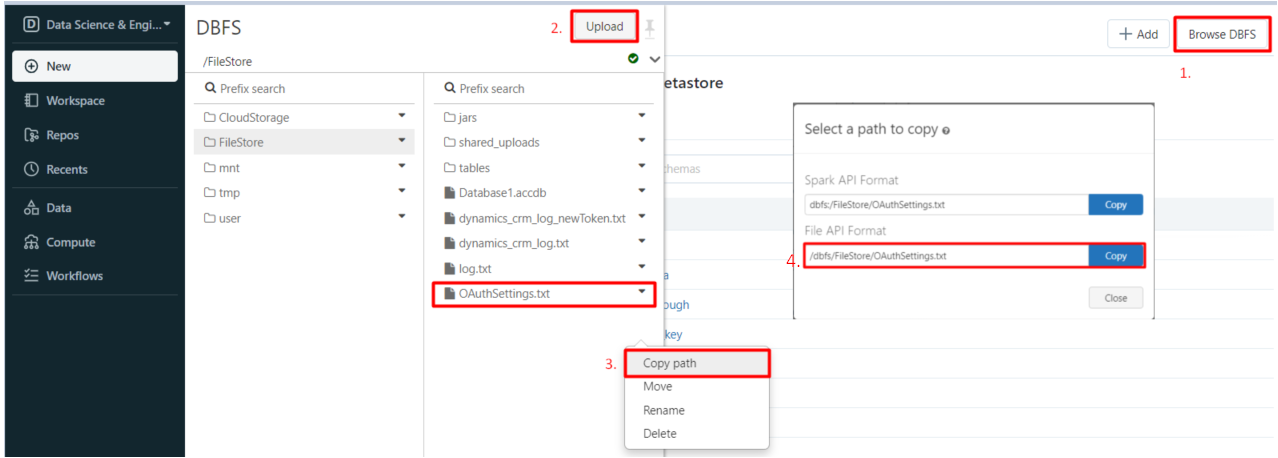
Please ensure to copy the File API Format path – it allows you to read and write in the file. If the Spark API Format is used, the OAuthSettings.txt won’t be updated when the token is refreshed.
Afterward, in your Databricks notebook's connection string, assign the OAuthSettingsLocation property to the copied File API Format path, and configure the remaining connection properties accordingly to establish a connection with your data source. Below is the Python code to connect to Salesforce through OAuth authentication from Databricks:
#1. Connection information
OAuthClientId = "<Your_ClientId>"
OAuthClientSecret = "<Your_ClientSecret>"
RTK = "<Your_RTK>"
OAuthSettingsLocation_fileAPIFormat = "/dbfs/FileStore/OAuthSettings.txt";
driver = "cdata.jdbc.salesforce.SalesforceDriver"
connection_string= f"jdbc:salesforce:AuthScheme=OAuth;InitiateOAuth=REFRESH;OAuthClientId={OAuthClientId};OAuthClientSecret={OAuthClientSecret};OAuthSettingsLocation={OAuthSettingsLocation_fileAPIFormat};RTK={RTK};"
#2. Reading the data
remote_table = (
spark.read.format("jdbc") \
.option("driver", driver)
.option("url", connection_string)
.option("dbtable", "sys_tables")
.load()
)
#3. Querying the data
display(remote_table.select("tableName"))
Please reach out to [email protected] if you run into any issues.
